Métriques DORA
28 minutes de lecture

.png?width=1200&name=Axify%20blogue%20header%20(30).png)
Dans l’environnement de croissance rapide actuel, il est essentiel de détecter les problèmes dans le système et de les résoudre le plus rapidement possible. Les équipes de développement logiciel doivent identifier les pannes dans le fonctionnement du système et le rétablir aisément.
Dans cet article, nous décoderons les différentes métriques MTTR et leurs variations: TTRS, MTBF, MTTA et MTTF.
Le MTTR a été introduit pour la première fois par le groupe DORA comme le délai de rétablissement du service (ou le temps moyen de restauration). Il s’agit de l’une des quatre métriques servant à distinguer les équipes de développement très performantes de celles moyennement performantes. Cette abréviation possède plusieurs synonymes que nous aborderons par la suite.
L’objectif principal de ces MTTR est d’indiquer la capacité d’une équipe et d’un produit à se rétablir rapidement après une panne. Analyser les métriques DORA permet aux team leads d’obtenir des informations véridiques pour évaluer leur performance. En observant les MTTR, les leads peuvent s’assurer de la stabilité de leur système et de l’amélioration de leurs processus internes.
MTTR est un acronyme utilisé pour désigner plusieurs métriques (KPI) se rapportant à la capacité de l’équipe informatique à résoudre des incidents. Il peut être associé au temps moyen de réparation, au temps moyen de restauration et au délai de rétablissement du service. Bien que ces termes puissent être confondus, ils présentent tous certaines particularités.
Comme mentionné ci-haut, le temps moyen de réparation fait référence au temps nécessaire pour réparer une composante ou un système défectueux et le rendre fonctionnel à nouveau. Cette métrique inclut le temps nécessaire pour diagnostiquer le problème, se préparer à la réparation (entre autres en collectant les documents), effectuer la réparation elle-même et puis confirmer que le système est à nouveau opérationnel.
Le temps moyen de réparation calcule le temps passé sur la réparation de problèmes en moyenne.
%20calculation%20based%20on%20total%20repair%20time%20and%20total%20number%20of%20failures.webp?width=851&height=496&name=mean%20time%20to%20repair%20(MTTR)%20calculation%20based%20on%20total%20repair%20time%20and%20total%20number%20of%20failures.webp)
Par exemple, si vous avez consacré 60 heures à la maintenance non planifiée d’un bien qui est tombé en panne 10 fois en 1 an, le temps moyen de réparation serait de 6 heures. Le temps de réparation commence à partir du moment où l’on découvre l’incident.
Le MTTR est souvent utilisé pour l’entretien et est une métrique cruciale dans les industries où le temps de fonctionnement des systèmes est essentiel. Il fournit des informations sur la vitesse à laquelle une organisation peut répondre aux défaillances et les régler, ce qui est crucial pour minimiser les temps d’arrêt.
Le MTTR affecte de nombreux points de la gestion opérationnelle, et pas seulement la réparation des défauts.
Le temps moyen de restauration et le délai de rétablissement du service peuvent être utilisés de manière interchangeable. Il reflète le temps nécessaire pour restaurer un système ou une application à son état fonctionnel antérieur après une défaillance qui ne nécessite pas obligatoirement une réparation, comme une panne temporaire ou une interruption de service. Il mesure le temps requis pour que les opérations normales reprennent après une perturbation, ce qui peut inclure le basculement vers des systèmes de secours.
Le temps moyen de restauration ou le délai de rétablissement sont calculés en mesurant le temps d’arrêt total sur une période précise et en la divisant par le nombre total d’incidents survenus durant la période.

Par exemple, prenez un système qui tombe en panne trois fois par an. Le premier incident a pris 3 heures à être restauré, le second a pris deux heures et le troisième a pris 1 heure, pour un total de 6 heures. Le MTTR pour ce mois serait de 6 heures de temps d’arrêt total / 3 incidents = 2 heures.
Le MTTR consiste à ramener le système à son état fonctionnel optimal, ce qui peut signifier différentes choses en fonction de la conception des plans de résilience et d'urgence du système. Il peut également inclure le temps nécessaire pour restaurer les données à partir des sauvegardes et réparer le problème d'origine.
Il est bon de prendre en compte les chiffres et les aspects qualitatifs de la réponse aux incidents. Cela vous aide à découvrir la capacité de l'équipe à restaurer le système et à le rendre plus fiable. Le temps moyen de restauration ou de rétablissement peut vous aider à:
En général, le délai moyen de réponse fait référence au temps moyen nécessaire pour répondre à un incident ou à une demande de service après que celui-ci ou celle-ci ait été signalé. Il mesure la vitesse à laquelle une équipe reconnaît l'existence d'un problème et commence à prendre des moyens pour le résoudre.
La formule pour calculer le temps moyen de réponse est la suivante :
%20en%20fonction%20du%20temps%20total%20de%20r%C3%A9ponse%20aux%20incidents%20et%20du%20nombre%20d%E2%80%99incidents.webp?width=851&height=496&name=calcul%20du%20temps%20moyen%20de%20r%C3%A9ponse%20(MTTR)%20en%20fonction%20du%20temps%20total%20de%20r%C3%A9ponse%20aux%20incidents%20et%20du%20nombre%20d%E2%80%99incidents.webp)
Ainsi, si votre système est tombé en panne pendant une heure lors de deux incidents distincts survenus en 24 heures — 60 minutes divisées par deux font 30, votre MTTR est de 30 minutes.
Le temps moyen de réponse est une mesure précieuse utilisée dans la gestion des incidents pour évaluer l'efficience et l'efficacité des efforts de réponse. Globalement, le temps moyen de réponse est un indicateur essentiel pour évaluer et améliorer les processus de gestion des incidents, contribuant ainsi à la fiabilité et à la résilience de vos systèmes et services.
Globalement, la mesure du temps moyen de réponse permet aux organisations d'optimiser leurs processus de gestion des incidents.
Le TTRS est une métrique DORA qui indique le temps nécessaire à une organisation pour se remettre d'une panne de production.
La formule pour calculer le délai de rétablissement du service est la suivante :
%20en%20fonction%20du%20temps%20total%20de%20r%C3%A9tablissement%20et%20du%20nombre%20de%20d%C3%A9faillances.webp?width=851&height=496&name=calcul%20du%20d%C3%A9lai%20de%20r%C3%A9tablissement%20(TTRS)%20en%20fonction%20du%20temps%20total%20de%20r%C3%A9tablissement%20et%20du%20nombre%20de%20d%C3%A9faillances.webp)
Ainsi, si vous avez deux incidents, l'un nécessitant une heure de restauration du système et l'autre 30 minutes, la durée totale du TTRS sera de 45 minutes.
Le concept de «délai de rétablissement du service» est similaire au temps moyen de rétablissement, et certaines organisations peuvent utiliser ces termes de manière interchangeable. Il s'agit du temps nécessaire pour rétablir la situation après un incident de service. En le mesurant, on se concentre sur l'efficacité de la réponse et de la résolution de l'incident.
Comme le MTTR, le TTRS indique la capacité d'un système à rétablir son état après une défaillance. Le rétablissement efficace du fonctionnement normal améliore la stabilité opérationnelle globale, garantit des processus plus fluides et réduit les temps d'arrêt, ce qui a un effet positif sur la fiabilité du système.
Les métriques MTTR définies ci-dessus fournissent des informations utiles aux entreprises, mais leur calcul et leur interprétation peuvent poser des problèmes. Nous mentionnons ici quelques difficultés que vous pouvez rencontrer :
Même si votre code est robuste, bien testé et que le taux d'échec des modifications est raisonnable, il se peut que votre TTRS soit élevé. Si votre application tombe en panne et que le processus pour détecter, corriger et déployer la solution dont votre équipe dispose n’est pas excellent, votre TTRS sera médiocre. Il peut y avoir de multiples causes pour un mauvais TTRS, en voici quelques-unes.
Pour maintenir un TTRS faible, il convient de prendre en compte les meilleures pratiques suivantes :
Outre les métriques MTTR susmentionnées, l'industrie du logiciel dispose d'autres indicateurs clés de performance en matière d'échec. Ceux-ci sont peu utilisés, mais peuvent être significatifs dans certains cas.
Le MTBF indique le temps écoulé entre la défaillance précédente et la défaillance suivante d'un système. Cette métrique vous aide à prédire le temps dont vous disposez avant que le service ne tombe en panne à nouveau. Le MTBF est important parce qu'il indique que les défaillances au sein des applications se produiront à un moment ou à un autre, indépendamment de vos processus internes.
%20en%20fonction%20du%20temps%20total%20d%E2%80%99op%C3%A9ration%20et%20du%20nombre%20de%20d%C3%A9faillances.webp?width=851&height=496&name=calcul%20du%20temps%20moyen%20entre%20les%20d%C3%A9faillances%20(MTBF)%20en%20fonction%20du%20temps%20total%20d%E2%80%99op%C3%A9ration%20et%20du%20nombre%20de%20d%C3%A9faillances.webp)
Le délai moyen de détection calcule le temps qu'il faut pour que l'intervention proprement dite commence. Il indique la rapidité avec laquelle une équipe commence à répondre à un incident. Le suivi du temps moyen de détection est essentiel pour améliorer l'efficacité de l'analyse et de la résolution des incidents. Les équipes qui connaissent ces données peuvent minimiser le temps nécessaire pour analyser les alertes et déterminer les niveaux de priorité pour résoudre les défaillances.
.png?width=739&height=430&name=Nexapp%20blogue%20header%20(7).png)
Le MTTF est similaire au MTBF, mais il indique les défaillances qu'une équipe ne peut pas réparer, comme les serveurs de base de données, les lecteurs de bandes ou les disques durs défectueux. Les métriques représentent la durée attendue jusqu'à ce qu'une panne se produise. La valeur est mesurée en estimant les défaillances d'un système particulier au fil du temps et en calculant le temps moyen avant défaillance.
%20ou%20temps%20moyen%20de%20d%C3%A9tection%20en%20fonction%20du%20temps%20total%20entre%20les%20alertes%20et%20leur%20d%C3%A9tection%20et%20le%20nombre%20d%E2%80%99incidents.webp?width=851&height=496&name=calcul%20du%20temps%20moyen%20de%20r%C3%A9action%20(MTTA)%20ou%20temps%20moyen%20de%20d%C3%A9tection%20en%20fonction%20du%20temps%20total%20entre%20les%20alertes%20et%20leur%20d%C3%A9tection%20et%20le%20nombre%20d%E2%80%99incidents.webp)
Si les calculs manuels peuvent fournir des informations précieuses, un outil automatisé comme Axify.io permet de prédire efficacement le comportement du système et de suivre les indicateurs MTTR. Axify est une plateforme qui vous permet de surveiller tous les indicateurs de performance essentiels et vous aide à améliorer vos processus de développement et de livraison. Elle contient des tableaux de bord de qualité supérieure qui permettent un suivi constant des métriques DORA en temps réel, ce qui simplifie l'ensemble du processus. Elle permet également aux équipes de se concentrer sur les améliorations à apporter.
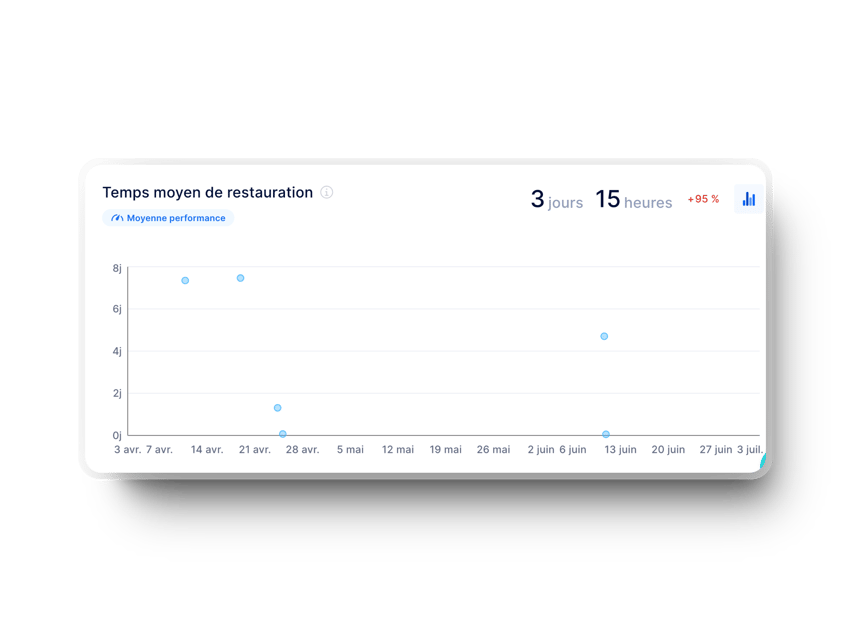
Axify met en œuvre les quatre métriques DORA :
Garder un œil sur le MTTR peut révéler des informations sur l'état de santé du système dans son ensemble. L'abaissement de ces paramètres améliorera la stabilité du système, favorisera la rationalisation des opérations et satisfera l'équipe.