Métriques DORA
48 minutes de lecture

.png?width=1200&name=Axify%20blogue%20header%20(1).png)
Les métriques DORA sont composées de cinq indicateurs qui fournissent des données objectives pour mesurer les performances des équipes de développement et favoriser l’amélioration des produits logiciels. Elles aident les développeurs à améliorer continuellement leurs pratiques, à livrer les logiciels plus rapidement et à s’assurer qu’ils soient stables. Apprenez tout ce qu’il faut savoir sur les métriques DORA en parcourant notre guide complet!
Obtenez votre copie PDF du guide complet des métriques DORA 👇
DORA est un acronyme pour DevOps Research and Assessment, une équipe qui étudie activement ce qui différencie une équipe de développement très performante d’une équipe peu performante. Dans le cadre d’un programme de sept ans, acquis par Google en 2018, ce groupe de recherche a analysé les pratiques et les capacités DevOps de plus de 32 000 professionnels du domaine et a pu identifier en 2020 quatre indicateurs clés pour mesurer les performances en matière de développement et de livraison de logiciels.
Outre un rapport DevOps officiel publié annuellement, l’équipe a également publié un livre blanc sur le retour sur investissement de la transformation DevOps, ainsi que le livre «Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations», coécrit par Dre Nicole Forsgren, co-fondatrice de l’équipe DORA et actuellement partenaire à Microsoft Research.
Puisqu’il existe de nombreux frameworks et méthodologies visant à améliorer la façon dont les équipes de développement bâtissent des produits et services logiciels, DORA souhaite mettre en lumière ce qui fonctionne et ce qui ne fonctionne pas de manière scientifique.
Depuis leur publication, les métriques DORA sont utilisées par les équipes DevOps partout dans le monde pour mesurer leur performance et savoir comment elles se comparent aux équipes de haute performance.
À haut niveau, la fréquence de déploiement et le délai nécessaire aux changements mesurent la vitesse, tandis que le taux d’échec des changements et le temps de récupération d'un échec de déploiement mesurent la stabilité. En mesurant ces indicateurs, et en itérant continuellement pour les améliorer, une équipe peut obtenir de meilleurs résultats commerciaux.
En effet, les études de l’équipe DORA démontrent que les équipes aux performances de livraison élevées sont deux fois plus susceptibles d’atteindre ou de dépasser leurs objectifs de performance organisationnelle.
En 2021, l’équipe DORA a ajouté une cinquième métrique, la fiabilité, à la liste des éléments ayant un impact sur les performances organisationnelles. Dans cet article, nous couvrirons les quatre premières métriques, soit la fréquence de déploiement, le délai nécessaire aux changements, le taux d’échec des changements et le temps de récupération d'un échec de déploiement.

Comme son nom l’indique, la fréquence de déploiement fait référence à la fréquence des mises en production : elle mesure la fréquence à laquelle une équipe déploie un changement en production.
Les équipes de développement qui ont de meilleures performances de livraison ont tendance à effectuer des livraisons plus petites et beaucoup plus fréquentes, afin de fournir de la valeur plus fréquemment aux utilisateurs, améliorer la fidélisation des clients et garder une longueur d’avance sur la concurrence.
À quelle fréquence votre organisation déploie-t-elle du code en production ou le rend-elle accessible aux utilisateurs finaux?
| Performance élite | Haute performance | Performance moyenne | Performance faible |
| Sur demande | Entre une fois par jour et une fois par semaine | Entre une fois par semaine et une fois par mois | Entre une fois par semaine et une fois par mois |
Source : 2023 Accelerate State of DevOps, Google.
La fréquence de déploiement, comme son nom l’indique, calcule le nombre de déploiements effectués par l’équipe pour une période donnée (par mois, semaine ou jour, par exemple). Une fréquence de déploiement élevée est un bon indicateur de la capacité de l’équipe à apporter des changements. De plus, une fréquence de déploiement stable (donc une cadence de déploiement régulière) peut être le reflet d’une équipe agile livrant de la valeur en continu, ce qui permet de réduire la boucle de rétroaction, un avantage inestimable pour l’équipe et les utilisateurs.
Peu importe où se situe votre équipe dans le tableau ci-haut, voici quelques pistes pour vous améliorer :
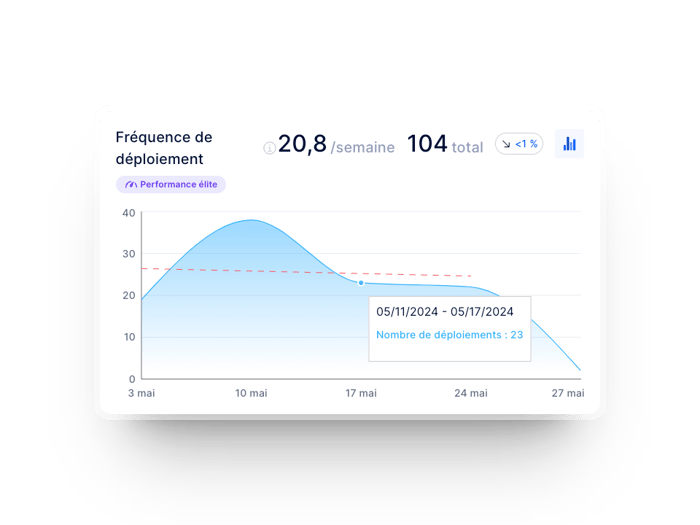
La fréquence de déploiement d’une équipe de développement dans Axify
Cet indicateur mesure le temps écoulé entre le premier commit et son déploiement en production. Il est utilisé pour mieux comprendre le temps de cycle de l’équipe et analyser sa réactivité face à l’évolution constante des demandes et des besoins des utilisateurs. Plus le délai nécessaire aux changements est bas, plus l’équipe est réactive et ajoute de la valeur rapidement.
Afin de mesurer le délai nécessaire aux changements, deux données sont nécessaires : l’heure exacte du premier commit et l’heure exacte du déploiement dans lequel il a été fait. La durée moyenne est ensuite utilisée comme indicateur de performance, les équipes qui ont une meilleure performance de livraison sont capables de passer du commit à la livraison en production en moins d’un jour.
Combien de temps faut-il pour passer du premier commit au code livré en production?
| Performance élite | Haute performance | Performance moyenne | Performance faible |
| Moins d'un jour | Entre un jour et une semaine | Entre une semaine et un mois | Entre une semaine et un mois |
Source : 2023 Accelerate State of DevOps, Google
Le délai nécessaire aux changements est un indicateur de la rapidité avec laquelle une équipe livre des changements aux utilisateurs. Il représente l’efficacité du flow, la complexité du code et la capacité de l’équipe. Des délais de livraison plus courts sont préférables, car ils permettent une boucle de rétroaction plus courte sur ce qui est développé et de corriger le tir plus rapidement.
Les déploiements peuvent être retardés pour diverses raisons, notamment la peur de l’échec au déploiement ou le refus d’une livraison partielle : il est donc important que les équipes de développement aient une idée précise du temps nécessaire pour mettre les changements en production. Cette mesure est particulièrement utile pour les entreprises ou gestionnaires devant suivre plusieurs contextes ou équipes, puisqu’elle devient un indicateur de référence.

Peu importe où se situe votre équipe dans le tableau ci-haut, voici quelques pistes pour vous améliorer :
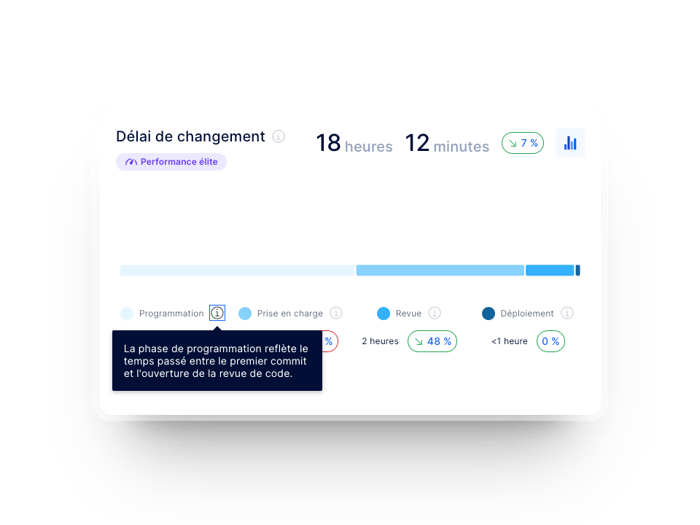
Le délai nécessaire aux changements d’une équipe de développement dans Axify
Conseil | Analyser les étapes de votre processus pour cibler les opportunités d’automatisation peut être bénéfique pour votre équipe. En réduisant les manipulations humaines (tant au niveau des tests que des automatisations), vous contribuez à accélérer la cadence de livraison. Ajoutez à cela un remboursement progressif de la dette technique et un meilleur découpage des items, et vous serez sur la bonne voie pour réduire le délai nécessaire aux changements!
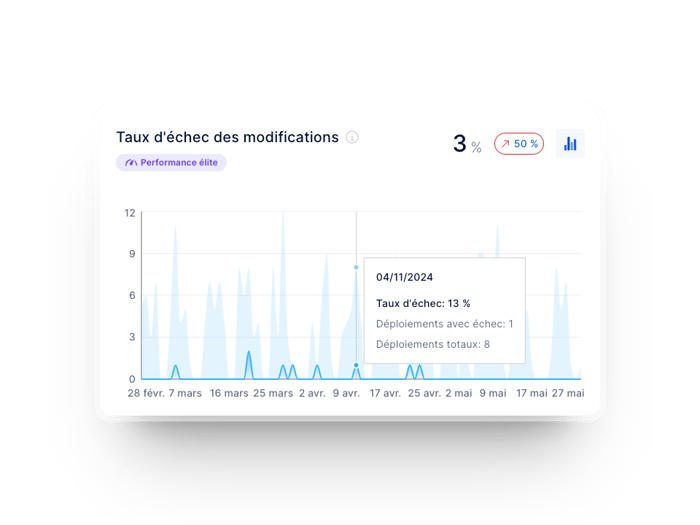
Cette métrique capte le pourcentage de modifications apportées à un code qui ont ensuite entraîné des incidents, des retours en arrière ou tout autre type d’échec de production. Selon le rapport DORA, les entreprises les plus performantes se situent autour de 5%.
La partie la plus délicate pour la plupart des équipes consiste à définir ce qu’est un «incident». Il peut s’agir d’une non-disponibilité du système (partielle ou complète), d’une fonctionnalité non utilisable, d’un bogue critique, majeur ou tout type de bogue. Selon DORA, il s’agit de changements apportés à la production ou aux versions destinées aux utilisateurs qui entraînent une dégradation du service (par exemple, une détérioration ou une interruption du service) et qui nécessitent ensuite des mesures correctives (par exemple, un hotfix, un rollback, un fix forward ou un patch). Une définition trop large ou trop restrictive pourrait nuire à l’équipe et la réponse dépend fortement du contexte de celle-ci.
Quel pourcentage des modifications apportées à la production ou aux utilisateurs finaux entraîne une dégradation du service?
| Performance élite | Haute performance | Performance moyenne | Performance faible |
| 5% | 10% | 15% | 64% |
Source : 2023 Accelerate State of DevOps, Google
Il s’agit d’un indicateur de qualité et de stabilité du code. Cette métrique montre le pourcentage de changements effectués qui entraînent un incident. Comme mentionné précédemment, le type d’incident considéré pour cette métrique est propre à chaque équipe. Mais il est important de comprendre qu’un taux d’échec élevé implique une augmentation du temps passé à retravailler sur des fonctionnalités existantes, donc une diminution du temps alloué à livrer de la nouvelle valeur aux utilisateurs. Bien que ce ne soit pas une métrique de temps à proprement parler, le taux d’échec des changements peut avoir des implications importantes sur votre capacité à créer de la valeur rapidement.
Un faible taux d’échec des changements montre que l’équipe identifie les erreurs et les bogues d’infrastructure avant le déploiement du code. C’est le signe d’un processus de déploiement solide et de la livraison de logiciels de haute qualité. L’objectif de l’équipe DevOps devrait être de réduire le taux d’échec des modifications afin de garantir la disponibilité et le bon fonctionnement du logiciel.
Peu importe où se situe votre équipe dans le tableau ci-haut, voici quelques pistes pour vous améliorer :
Conseil | Les équipes qui ne déploient pas beaucoup de changements verront moins d’incidents, mais cela ne signifie pas nécessairement qu’elles ont plus de succès avec les changements qu’elles déploient. Les équipes qui déploient fréquemment peuvent voir un nombre plus élevé d’incidents, mais si le taux d’échec des changements est faible, ces équipes auront un avantage en raison de la rapidité de leurs déploiements et de leur taux de réussite global.
Le temps de récupération d'un échec de déploiement mesure le temps nécessaire à un service pour rebondir après un incident ou une dégradation du service. Quel que soit le niveau de performance d’une équipe, des pannes ou des incidents imprévus se produiront. Et comme les incidents ne peuvent être évités, c’est vraiment le temps qu’il faut pour restaurer ou récupérer un système ou une application qui fait la différence.
Cette métrique est importante, car elle encourage les développeurs à construire des systèmes plus fiables, disponibles et résilients. Elle est généralement calculée en suivant le temps moyen entre le signalement de l’incident et le moment où sa restauration est déployée. Pour les équipes les plus performantes, il s’agit d’être capable de restaurer le service en moins d’une heure.
Combien de temps faut-il pour restaurer le service après une panne, une dégradation ou l’introduction d’un bogue ayant un impact sur les utilisateurs?
|
Performance élite |
Haute performance |
Performance moyenne |
Performance faible |
|
Moins d'une heure |
Moins d'un jour |
Entre un jour et une semaine |
Entre un et six mois |
Le temps de récupération d'un échec de déploiement indique le temps de réponse d’une équipe et l’efficacité du processus de développement. Lorsqu’il est bas, il démontre qu’une équipe réagit et résout les problèmes rapidement pour garantir la disponibilité et le bon fonctionnement du produit.
De plus, la capacité d’une équipe à se rétablir rapidement peut avoir un impact positif sur le niveau de confiance des utilisateurs et amener plus d’aisance de la part des dirigeants face aux expérimentations. C’est donc un avantage concurrentiel non négligeable!
Absence de tests automatisés
Dépendance vers un membre externe à l’équipe ou manque d’accès à certaines composantes du système
Pas de changement de focus dans l’équipe pour résoudre l’incident
Processus de gestion des incidents inefficace
Difficulté de déployer en production rapidement
Pas de processus de restauration à une version antérieure (rollback)
Outils inefficaces
Peu importe où se situe votre équipe dans le tableau ci-haut, voici quelques pistes pour vous améliorer :
Favoriser une surveillance en continu et améliorer l’observabilité
Donner la priorité à la restauration lorsqu’une défaillance se produit
Essayer les feature flags pour être en mesure de désactiver rapidement un changement sans causer trop de perturbations
Livrer de petites itérations pour qu’il soit plus facile de découvrir et de résoudre les problèmes
Investir davantage dans les tests automatisés et utiliser une stratégie de tests orientés sur les comportements
Documenter le processus de gestion des incidents et former les membres de l’équipe sur la façon de réagir en cas d’incidents
Lorsque c’est applicable, automatiser plusieurs étapes du processus de gestion des incidents et désigner des responsables pour les étapes qui doivent être réalisées manuellement
Conseil | Équilibrez vitesse et stabilité! Permettez-vous parfois de ralentir pour mieux accélérer, en réduisant par exemple le travail en cours (WIP). Évitez de mettre en production des changements soudains au détriment d’une solution de qualité. Plutôt que de déployer une solution rapide, assurez-vous que le changement que vous apportez est durable et testé. Vous devriez suivre le temps moyen de récupération d'un échec de déploiement dans le temps pour voir comment votre équipe s’améliore et viser une croissance régulière et stable.

Le temps de récupération d'un échec de déploiement dans Axify
Pour s’améliorer, il faut deux éléments : un point de départ et un objectif à atteindre. Les métriques DORA donnent aux équipes de développement des objectifs concrets, qui peuvent ensuite être décomposées en résultats clés. En sachant quelles données suivre au fil du temps, les développeurs vont ajuster leur comportement pour améliorer la mesure de leur côté, ce qui aura un impact sur l’efficacité de l’équipe et des processus.
De plus, les variations dans les résultats des métriques DORA vous aideront à cibler rapidement les points à améliorer en ce qui concerne le processus de livraison et à repérer les problèmes tels que l’inefficacité des tests.
Les métriques DORA sont des métriques fiables résultant d’études scientifiques à jour. Comme les quatre métriques sont reliées entre elles, elles sont difficiles à tricher : vous avez donc un portrait réaliste de votre situation. Elles permettent aussi de comparer votre équipe au reste de l’industrie, d’identifier les possibilités d’amélioration et d’apporter des changements pour optimiser vos résultats à plusieurs niveaux.
Les entreprises qui rationalisent leur processus de développement et de livraison augmentent la valeur des logiciels qu’elles développent et sont plus performantes à long terme. Le suivi des performances à l’aide des métriques DORA permet aux équipes DevOps de prendre des décisions fondées sur des données, et non sur des intuitions.
De plus, les métriques DORA aident à aligner les objectifs de développement sur les objectifs commerciaux. Du point de vue de la gestion des produits, ils permettent de savoir comment et quand les équipes de développement peuvent répondre aux besoins des clients.
Ces dernières années, la gestion de la chaîne de valeur (Value Stream Management) est devenue un élément important du développement logiciel. Dans ce contexte, les métriques DORA jouent un rôle indispensable, car les équipes qui se mesurent ont tendance à s’améliorer en continu. Ainsi, lorsque les équipes DevOps utilisent les métriques DORA, elles constatent généralement une augmentation de la valeur au fil du temps.
En tant qu’ensemble de repères DevOps éprouvés qui sont devenus la norme dans le secteur, les métriques DORA fournissent une base pour ce processus. Elles identifient les points d’inefficacité ou de gaspillage, et vous pouvez utiliser ces informations pour rationaliser et réduire les goulots d’étranglement dans vos flux de travail, par exemple en décortiquant le délai nécessaire aux changements en étape pour observer les étapes qui bloquent le processus. Lorsque les indicateurs DORA de vos équipes s’améliorent, l’efficacité de l’ensemble de la chaîne de valeur s’améliore avec elles.
En outre, les métriques DORA vous permettent de vous mesurer et vous améliorer pour ultimement :
Livrer plus rapidement, en garantissant une meilleure stabilité
Offrir plus de valeur aux clients en garantissant des itérations rapides et une meilleure réactivité au retour d’information
Augmenter plus rapidement la valeur commerciale d’un produit
Les mesures DORA donnent également un aperçu des performances des équipes. En examinant le taux d’échec des changements et le temps de récupération d'un échec de déploiement, les responsables de l’ingénierie peuvent s’assurer que leurs équipes construisent des produits robustes avec des temps d’arrêt minimaux. De même, le suivi de la fréquence de déploiement et du délai nécessaire aux changements permet d’avoir l’assurance que l’équipe travaille rapidement. Ensemble, ces mesures donnent un aperçu de l’équilibre entre vitesse et qualité au sein de l’équipe.
En comparant ces quatre indicateurs clés, on peut évaluer dans quelle mesure l’organisation parvient à équilibrer vitesse et stabilité. Par exemple, si le temps moyen de récupération d'un échec de déploiement est inférieur à une semaine avec des déploiements hebdomadaires, mais que le taux d’échec des changements est élevé, alors il se peut que l’équipe précipite les déploiements alors qu’il manque de tests automatisés, ou elles peuvent ne pas être en mesure de prendre en charge les changements qu’elles déploient. D’autre part, si les déploiements ont lieu une fois par mois et que le temps de récupération d'un éhec de déploiement et le taux d’échec des changements sont élevés, l’équipe passe peut-être plus de temps à corriger le code qu’à améliorer le produit. Tout est une question de contexte!
La plupart du temps, les environnements et les données sont décentralisés, c’est-à-dire que les données sont dispersées dans différentes sources à travers l’organisation. De plus, les extraire peut être complexe lorsqu’elles ne sont disponibles qu’au format brut. Enfin, les données doivent être transformées et combinées en unités calculables pour permettre aux équipes de développement d’en tirer tous les avantages. En plus du temps requis pour faire ces manipulations, calculer manuellement les données laisse place à l’interprétation, ce qui présente un risque d’erreur ou de communiquer la mauvaise information.
Comme toutes les données, les mesures DORA doivent être mises en contexte et il faut considérer l’histoire que ces quatre métriques racontent ensemble. Le délai nécessaire aux changements et la fréquence de déploiement donnent un aperçu de la cadence d’une équipe et de la rapidité avec laquelle elle répond aux besoins en constante évolution des utilisateurs. D’autre part, le temps moyen de récupération d'un échec de déploiement et le taux d’échec des changements indiquent la stabilité d’un produit logiciel et la réactivité de l’équipe en cas d’interruption ou de défaillance du service. Seul un professionnel qui comprend la réalité de l’équipe de développement sera en mesure de bien interpréter ces données pour contribuer à leur amélioration continue.
Chez Axify, nous intégrons les métriques DORA à nos tableaux de bord pour voir tous les facteurs permettant de soutenir votre équipe dans l’amélioration continue d’un seul coup d’œil. Pas d’extraction de données ni d’ambiguïté sur leur interprétation. Tout est à portée de main pour rester dans le feu de l’action! De plus, puisque toutes vos équipes utiliseront la même structure et la même méthode d’extraction, il sera plus facile pour vous de comparer des pommes avec des pommes.
Lorsque vous aurez choisi un outil vous permettant de suivre les métriques DORA, ne focalisez pas trop sur les métriques dans un premier temps. Commencez à collecter des données, suivez les métriques pendant quelques semaines, puis analysez ce que vous devez améliorer.
Ensuite, établissez des objectifs d’amélioration : concentrez-vous sur votre produit et sa croissance, ainsi que sur la croissance de votre équipe et l’amélioration des processus. Considérez les indicateurs DORA comme un ensemble d’indicateurs de ce que vous pouvez faire pour avoir un impact positif sur le produit et ses résultats commerciaux.
En réalité, les métriques ne sont qu’un outil. L’important, c’est que l’équipe de développement souhaite améliorer son efficacité et qu’elle utilise des indicateurs pour savoir si elle progresse dans ses efforts d’amélioration continue. Donnez à votre équipe les outils dont ils ont besoin pour réussir à apporter les meilleurs changements qui aideront votre équipe à atteindre ses objectifs.
Lorsque vos métriques DORA s’améliorent, vous pouvez être sûr que vous avez pris les bonnes décisions pour améliorer la performance de votre équipe et que vous apportez une plus grande valeur à vos clients.
Axify regroupe plusieurs fonctionnalités pour vous aider à visualiser la progression de ces métriques pour votre (ou vos!) équipe(s). Premièrement, nos intégrations avec les outils que vous utilisez déjà comme GitLab, GitHub et Azure DevOps recueillent et traitent les données alimentant les métriques DORA. Deuxièmement, notre outil de création et suivi d’objectif vous permet de sélectionner les métriques à améliorer et d’indiquer la variation souhaitée sur un horizon temporel de votre choix. Ces tableaux de bord vous permettent de suivre vos progrès au fil du temps.
Pour plus d’informations sur la façon dont Axify aide les équipes de développement à mesurer les indicateurs de performance DORA, contactez-nous ou demandez une démonstration.