En matière de DevOps, il est essentiel de suivre les bonnes mesures pour optimiser les performances et garantir la fiabilité du système.
Si vous cherchez à comprendre quelles sont les mesures DevOps les plus importantes et comment elles contribuent au succès, vous êtes au bon endroit.
Dans cet article de blog, nous allons nous pencher sur les principales mesures DevOps, sur la manière de les suivre et sur d'autres détails essentiels.
Commençons.

Que sont les indicateurs DevOps ?
Les métriques DevOps sont des indicateurs mesurables qui évaluent la performance, la fiabilité et l'efficacité des processus et des équipes DevOps (développement et opérations informatiques). Fondamentalement, ils donnent un aperçu de la santé du pipeline de livraison de logiciels, ce qui peut vous aider à comprendre la qualité et la rapidité des cycles de déploiement de votre organisation.
Pourquoi suivre les indicateurs DevOps ?
Le suivi des indicateurs DevOps est essentiel pour les raisons suivantes :
- Optimiser la vitesse de livraison
- Améliorer la fiabilité du système
- Suivi du progrès
- Identifier les goulots d'étranglement
- Améliorer la satisfaction du client
- Assurer l'alignement du développement logiciel sur les objectifs de l'entreprise
Métriques DevOps vs. DORA
Les indicateurs DevOps et DORA (DevOps Research and Assessment) sont interconnectés, mais ils jouent des rôles différents dans l'écosystème de livraison de logiciels. Il est toutefois important de préciser que les métriques DORA sont un sous-ensemble du cadre DevOps plus large, qui se concentre sur les résultats quantifiables dans ce contexte plus vaste.
DevOps est une méthodologie holistique qui renforce la collaboration entre les équipes de développement et les équipes opérationnelles afin d'améliorer le pipeline de livraison de logiciels grâce à la collaboration, l'automatisation et la rationalisation des flux de travail. D'autre part, les métriques DORA sont un ensemble spécifique d'indicateurs de performance conçus pour mesurer la productivité des développeurs et évaluer le succès et l'efficacité des pratiques DevOps.
La plupart des discussions sur les métriques DORA tournent autour des quatre indicateurs largement reconnus :
Obtenez votre copie PDF du guide complet des métriques DORA 👇
Toutefois, ce cadre ne s'arrête pas là : il met l'accent sur la formation d'équipes hautement performantes en se concentrant sur des capacités supplémentaires, telles que :
- La gestion allégée des produits : Veiller à ce que les équipes donnent la priorité à des tâches axées sur la valeur et alignées sur les objectifs de l'entreprise.
- Culture d'équipe : Favorise la collaboration et le partage des responsabilités entre les équipes de développement et d'exploitation.
- Pratiques de livraison continue : Réduit les délais de reprise des déploiements et améliore la fiabilité.
12 indicateurs DevOps essentiels
Jetons un coup d'œil à quelques-unes des mesures DevOps importantes à surveiller :
1. Fréquence de déploiement
- Objectif: Mesure la fréquence à laquelle votre équipe déploie les modifications de code en production.
- Ce que cela indique: Des déploiements fréquents indiquent un flux de travail bien optimisé avec des déploiements de fonctionnalités plus rapides et des corrections rapides. Par exemple, si votre équipe parvient à effectuer des déploiements quotidiens ou même plusieurs déploiements par jour, cela montre sa capacité à gérer de gros volumes de mises à jour avec un minimum de risques.
Conseil de pro: vous pouvez utiliser Axify pour rechercher des modèles de fréquence de déploiement et évaluer comment l'automatisation de vos processus DevOps peut encore améliorer la vitesse de déploiement et réduire les retards.
%20dans%20axify.webp?width=851&height=638&name=graphique%20sur%20la%20fr%C3%A9quence%20de%20d%C3%A9ploiement%20(m%C3%A9trique%20dora)%20dans%20axify.webp)
2. Temps de reprise après un échec de déploiement (anciennement MTTR)
- Objectif: met en évidence la rapidité avec laquelle votre équipe se remet d'un échec de déploiement, ce qui témoigne de sa réactivité et de sa résilience. Il est essentiel de garder un œil sur cette mesure pour réduire l'impact des échecs en production.
- Ce qu'il indique: Visez des délais de reprise après un échec de déploiement plus courts, car cela démontre des mécanismes de réponse aux incidents robustes et un dépannage rapide pour garantir la stabilité du système et améliorer la fidélisation des clients.
Conseil de pro: Utilisez les informations fournies par Axify pour rationaliser les processus de réponse aux incidents. Vous réduirez ainsi le délai entre l'échec et la résolution de l'incident.
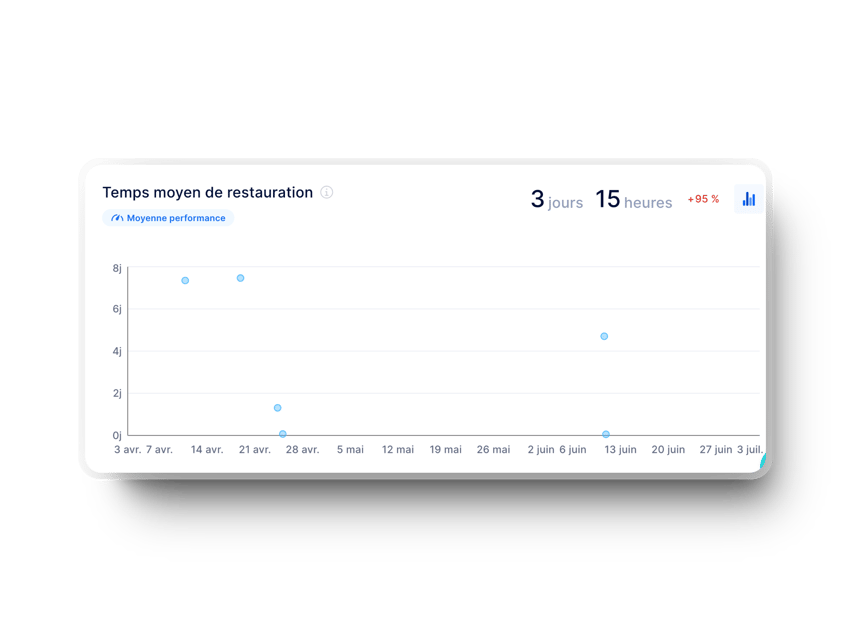
3. Délai de mise en œuvre des changements
- Objectif: mesure le temps qui s'écoule entre la première validation d'un changement et son déploiement. Fondamentalement, il révèle l'efficacité avec laquelle le changement traverse le pipeline de développement logiciel pour atteindre la production.
- Ce qu'il indique: Si le délai d'exécution des modifications est plus court, cela signifie que votre équipe est en mesure de fournir des mises à jour rapidement, ce qui est le signe d'un flux de travail optimisé.

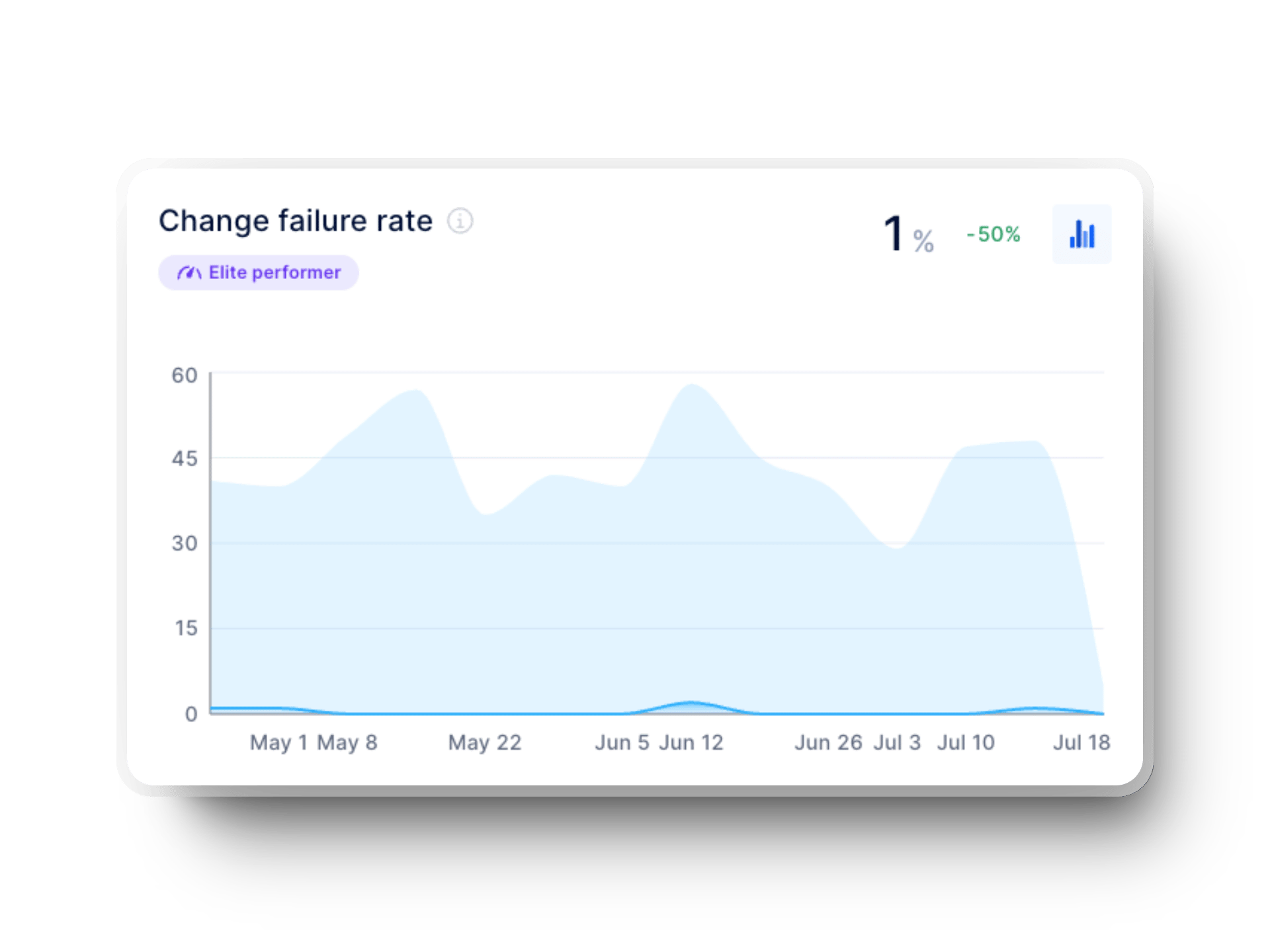
4. Taux d'échec des modifications
- Objectif: Calculer le pourcentage de déploiements qui aboutissent à des échecs ou nécessitent un retour en arrière, ce qui donne une idée de la qualité du code et de la fiabilité du processus.
- Ce qu'il indique: Lorsque votre équipe obtient régulièrement un faible taux d'échec des changements, cela signifie que vos processus d'assurance qualité sont solides. En revanche, un taux élevé peut indiquer des lacunes dans les tests ou un manque de validation automatisée.
Conseil de pro: introduisez des outils de contrôle continu tels qu'Axify pour surveiller le taux d'échec et mettre en œuvre des mesures correctives afin d'améliorer vos résultats. Vous pouvez également utiliser Axify pour repérer les problèmes plus tôt dans le cycle de développement et prévenir les défaillances en production qui nécessitent des changements.
5. Temps de cycle
- Objectif: le temps de cycle mesure le temps nécessaire pour qu'une tâche passe de l'état "en cours" à l'état "terminé", ce qui donne une idée de l'efficacité du flux de travail de votre équipe.
- Ce qu'il indique: L'essentiel est de viser des durées de cycle courtes, car elles mettent en évidence l'efficacité des flux de travail. Des durées plus longues peuvent indiquer des contraintes de ressources ou des retards dans des étapes spécifiques.
Conseil de pro: Minimisez les transferts de tâches entre les membres de l'équipe ou les services afin d'éviter les retards qui allongent la durée du cycle. Par exemple, envisagez d'intégrer l'assurance qualité plus tôt dans le flux de travail en adoptant une approche de la qualité fondée sur le principe du "shift-left". Cela signifie que l'équipe d'assurance qualité doit être impliquée dans la phase de planification afin de créer des scénarios de test. Les développeurs peuvent utiliser ces scénarios pour automatiser les tests et identifier les problèmes potentiels plus tôt, ce qui garantit un processus plus fluide.

6. Temps moyen de détection (MTTD) et temps moyen d'acquittement (MTTA)
Ces mesures étant similaires, nous les regrouperons dans une même section :
MTTD (Temps moyen de détection)
- Objectif: mesure la rapidité avec laquelle votre équipe identifie un problème une fois qu'il se produit, en se concentrant sur l'efficacité de vos systèmes de surveillance et d'alerte. Un système de détection robuste minimise les pannes non planifiées en fournissant des informations en temps opportun.
- Ce qu'il indique: Un MTTD plus court reflète l'efficacité de vos outils et processus de surveillance. S'il est élevé, il peut signaler des lacunes dans la couverture des alertes ou des retards dans l'identification des anomalies. Selon les meilleures pratiques de gestion des incidents, l'amélioration de la qualité de la détection passe souvent par l'affinement de la configuration des alertes et l'adoption d'outils de surveillance prédictive.
MTTA (délai moyen d'acquittement)
- Objectif: Suivre la rapidité avec laquelle votre équipe répond à une alerte, en mettant l'accent sur l'élément humain de la gestion des incidents.
- Ce qu'il indique: Un MTTA faible indique une équipe opérationnelle réactive et bien préparée, capable de hiérarchiser et de traiter rapidement les incidents. Un MTTA élevé peut indiquer que les processus de remontée des alertes ne sont pas clairs ou que le personnel n'est pas en mesure de répondre 24 heures sur 24 à l'incident. La mise en œuvre de processus automatisés de remontée des alertes et d'outils de collaboration en temps réel peut contribuer à réduire le MTTA.
Suivez ces deux indicateurs clés de performance dans le cadre de vos meilleures pratiques de gestion des incidents afin de rationaliser votre flux de travail de réponse aux incidents. L'objectif est de réduire les temps d'arrêt et d'améliorer la fiabilité du système.
7. Travaux en cours (WIP)
- Objectif: surveiller le nombre de tâches ou de tickets sur lesquels l'équipe travaille activement, ce qui permet d'équilibrer la charge de travail.
- Ce qu'il indique: Un WIP élevé signale une surcharge potentielle, qui peut entraîner un allongement des délais et une réduction de la vitesse de déploiement. Un WIP équilibré permet de répartir les tâches de manière homogène afin de réduire les goulets d'étranglement et d'améliorer la concentration.
Conseil de pro: Limitez le WIP en fixant des seuils (par exemple, taille de l'équipe +1) et utilisez Axify pour surveiller cette mesure. Cela permet de maintenir l'efficacité des flux de travail et d'éviter les retards dans le pipeline de livraison des logiciels.
%20dans%20Axify%20pour%20les%20%C3%A9quipes%20de%20d%C3%A9veloppement%20logiciel.webp?width=851&height=638&name=Graphique%20du%20travail%20en%20cours%20(WIP)%20dans%20Axify%20pour%20les%20%C3%A9quipes%20de%20d%C3%A9veloppement%20logiciel.webp)
8. Temps de révision du code
- Objectif: Mesure le temps nécessaire à la révision et à l'approbation des modifications du code avant leur déploiement.
- Ce qu'il indique: De longs délais de révision peuvent retarder les déploiements et augmenter la durée du cycle. Des révisions de code plus rapides améliorent la vitesse de déploiement et maintiennent l'élan des processus DevOps.
9. Couverture des tests
- Objectif: Indique le pourcentage de code couvert par les tests automatisés.
- Ce qu'il indique: Une couverture de test plus élevée réduit le risque de défaillance en production, ce qui garantit un logiciel de meilleure qualité et minimise les taux de fuite des défauts.
10. Temps moyen entre les défaillances (MTBF)
- Objectif: Suivre le temps moyen entre les défaillances d'un système et donner une image fiable de sa stabilité.
- Ce qu'il indique: Un temps moyen entre les défaillances (MTBF) plus long indique une plus grande stabilité du système et des taux de défaillance plus faibles. Des défaillances fréquentes mettent en évidence des problèmes de fiabilité qui nécessitent votre attention.
11. Défauts échappés
- Objectif: Compter le nombre de bogues ou de problèmes trouvés en production qui n'ont pas été détectés pendant les tests. Nous vous conseillons de mettre en œuvre une politique "zéro bug" lorsque votre équipe aura mûri et se sera stabilisée. Vous voudrez vous attaquer immédiatement à tous les bogues que vous trouverez plutôt que de les différer. Cela crée une culture d'assurance qualité proactive.
- Ce que cela indique: Un nombre élevé de bogues indique des lacunes dans le processus de test et l'assurance qualité. Cela a un impact sur la fidélisation et la satisfaction des clients.
12. Temps de fonctionnement (Uptime)
- Objet : mesure la durée totale pendant laquelle un système, une application ou un service reste opérationnel et disponible sans interruption. Il s'agit d'une mesure essentielle pour évaluer la fiabilité du système et atteindre les objectifs de niveau de service (SLO et SLA).
- Ce qu'il indique : Un temps de disponibilité élevé démontre la stabilité du système et des performances constantes, ce qui signifie des interruptions minimales pour les utilisateurs finaux. À l'inverse, des temps d'arrêt fréquents indiquent des problèmes de fiabilité potentiels, des outils de surveillance insuffisants ou des lacunes dans le processus de réponse aux incidents.
Évaluer la maturité DevOps à l'aide de mesures clés
Lors de l'évaluation de la maturité DevOps, il convient de se concentrer sur les étapes suivantes :
1. Réactivité de la mise à l'échelle
Des mesures telles que la fréquence de déploiement et le délai d'exécution des changements sont cruciales pour estimer si vos processus peuvent évoluer efficacement à mesure que votre équipe s'agrandit.
Les équipes les plus performantes maintiennent des déploiements fréquents et des délais plus courts, même en cas d'augmentation de la charge de travail. Si la vitesse de déploiement ralentit au fur et à mesure que l'équipe s'agrandit, cela peut indiquer des inefficacités dans vos processus de déploiement, une automatisation insuffisante dans le pipeline ou des problèmes liés à la surcharge de communication.
Au fur et à mesure que les équipes s'agrandissent, vous devez être plus proactif en matière d'alignement et de collaboration. Dans le cas contraire, les retards se multiplient et l'efficacité diminue - un exemple parfait de la loi de Brooks. La règle générale inventée par Brooks en 1975 est que l'ajout de nouveaux membres à un projet logiciel en retard le rend plus tardif. La complexité de la coordination est un facteur probable.
Pour l'atténuer, il est possible de diviser les grandes équipes en unités plus petites et plus autonomes, dont les responsabilités sont découplées. Cette approche rationalise la communication au sein de l'équipe et réduit les dépendances, ce qui permet d'améliorer l'évolutivité et la réactivité.
2. Suivi de la fiabilité
Les mesures axées sur la fiabilité, telles que le temps de reprise en cas d'échec d'un déploiement (anciennement MTTR) et le taux d'échec des modifications, permettent d'évaluer la robustesse de votre système sous pression. Un faible taux d'échec des modifications reflète des déploiements stables, tandis que des délais de récupération plus courts indiquent la capacité de votre équipe à résoudre rapidement les défaillances en production.
Ces mesures permettent d'augmenter le nombre de déploiements par semaine sans compromettre la stabilité du système ou l'expérience de l'utilisateur final.
Voici quelques stratégies qui peuvent être mises en œuvre :
- Reculs automatisés: Mettre en œuvre des systèmes qui reviennent automatiquement à la dernière version stable lorsque des problèmes sont détectés. Cela permet de réduire les temps d'arrêt et de limiter l'impact sur l'expérience de l'utilisateur final.
- Réponse aux incidents par collaboration : Dans la réponse aux incidents par collaboration, tous les membres de l'équipe concernés collaborent immédiatement à la résolution d'un incident. En fait, chacun met en commun son expertise pour identifier et résoudre rapidement la cause première de l'incident. Cette méthode améliore la coordination de l'équipe dans les situations de forte pression et, par conséquent, accélère la résolution de l'incident.
- L'approche "réparer deux fois" : Vous devriez aller au-delà du traitement réactif des incidents en mettant en place des garde-fous qui empêchent la récurrence du même problème. Après avoir résolu l'incident initial, réexaminez le problème afin d'identifier les failles systémiques et d'introduire des correctifs à long terme. Cette approche contraste avec les réponses traditionnelles aux incidents par paliers, où les problèmes peuvent ne recevoir que des correctifs superficiels.
- Outils de surveillance: Utiliser des outils avancés pour obtenir des informations en temps réel sur l'utilisation des applications, la santé du système et les délais de récupération des déploiements. Ces outils permettent d'identifier et de résoudre de manière proactive les goulets d'étranglement avant qu'ils ne se transforment en problèmes plus importants.
Comment utiliser efficacement les indicateurs DevOps ?
Pour s'assurer que les indicateurs DevOps produisent des résultats significatifs, il convient de se concentrer sur les pratiques suivantes, qui peuvent faire l'objet d'une action :
- Adopter une surveillance continue: Le suivi en temps réel des indicateurs clés peut aider votre équipe à détecter les problèmes à un stade précoce, à réagir rapidement et à minimiser les perturbations. Il permet également d'identifier les schémas susceptibles d'entraver l'efficacité opérationnelle afin de faciliter le processus de livraison.
- Se concentrer sur l'efficacité du flux de travail: Les goulets d'étranglement dans le pipeline de développement, que ce soit au niveau des tests, des révisions ou des déploiements, peuvent retarder les progrès et entraver l'évolutivité. Grâce aux métriques DORA d'Axify et à la technologie Grâce à la cartographie de la chaîne de valeur, la Banque de développement du Canada a amélioré l'efficacité de son flux de travail et obtenu les résultats suivants :
- Accélération du temps de livraison jusqu'à 51 %
- Minimisation du temps de pré-développement jusqu'à 74%.
- Réduction du temps d'assurance qualité jusqu'à 81 %.
- Amélioration de 24 % de la capacité
- Gain de productivité annuel de 700 000$
- Automatiser tôt et souvent: L'automatisation améliore l'efficacité du flux de travail en éliminant les tâches répétitives telles que les tests et les déploiements. Votre équipe peut ainsi se concentrer sur les tâches stratégiques à forte valeur ajoutée qui stimulent l'innovation. En outre, elle garantit la cohérence, qui devient cruciale lorsque les équipes s'agrandissent ou gèrent des charges de travail accrues.
- Aligner les mesures sur les objectifs: Pour maximiser leur impact, les indicateurs DevOps doivent être directement liés aux objectifs de l'équipe et de l'entreprise. Par exemple, au lieu de fixer de vagues repères pour la fréquence de déploiement, concentrez-vous sur des indicateurs qui reflètent des améliorations significatives, comme des temps de récupération plus rapides ou une meilleure satisfaction des clients.
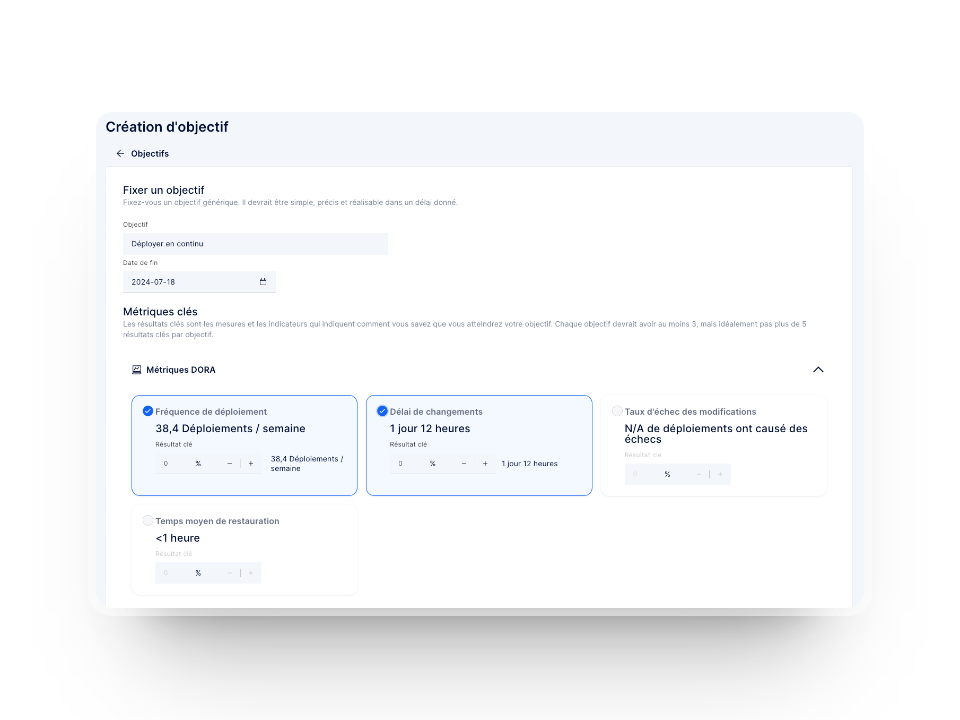
Les pièges à éviter dans la suivi des métriques DevOps
Bien que les métriques soient des outils puissants pour améliorer les processus, elles peuvent induire les équipes en erreur si elles ne sont pas appliquées correctement. Jetons un coup d'œil à quelques pièges courants qui peuvent affecter négativement vos progrès :
- Ne pas utiliser les lignes de code (LOC): Les lignes de code peuvent conduire à des conclusions erronées sur la productivité. Plus de code ne signifie pas nécessairement de meilleurs résultats ; au contraire, cela peut encourager une complexité inutile et perturber la maintenabilité. La véritable productivité se concentre sur la création de valeur et l'amélioration de l'expérience de l'utilisateur final, ce que les lignes de code ne parviennent pas à capturer.
- Soyez prudent avec le suivi de la vélocité: Bien que nous proposions des mesures de vélocité dans Axify, elles peuvent être mal interprétées si on leur accorde trop d'importance. Fondamentalement, cela se produit lorsque votre équipe se concentre uniquement sur la réalisation d'un plus grand nombre de tâches plutôt que sur la qualité des résultats. Cela conduit à des raccourcis, à des contrôles de qualité non effectués et à l'accumulation de la dette technique.
- Utiliser le débit plutôt que les points d'histoire : Le débit, qui mesure le nombre réel de tâches accomplies, donne une vision plus fiable de la capacité d'une équipe. Contrairement aux points d'histoire (story points), qui sont subjectifs et sujets à des incohérences, le débit s'appuie sur des données historiques pour prévoir les délais de livraison et fixer des attentes réalistes.
Conclusion : Améliorer le suivi indicateurs DevOps avec Axify
Les indicateurs DevOps sont essentiels pour mesurer les performances, identifier les goulets d'étranglement et favoriser l'amélioration continue de la livraison de logiciels. Axify peut vous aider dans tous ces domaines en vous proposant :
- Analyse prédictive: Utilise les données historiques pour prévoir les retards et les risques, ce qui permet une prise de décision proactive.
- Cartographie de la chaîne de valeur (VSM): Identifie les inefficacités dans les flux de travail afin de rationaliser les transitions de tâches et d'optimiser le pipeline de livraison de logiciels.
- Suivi de la daily: Fournit une vue concise de l'avancement et des priorités quotidiennes, ce qui permet à l'équipe de rester alignée sur les tâches critiques.
- Tableau de bord DORA Metrics: Il offre un aperçu en temps réel des mesures clés telles que la vitesse de déploiement et les temps de récupération pour aider les équipes à suivre leurs performances par rapport aux références de l'industrie.
- Objectifs et rapports: Permet de fixer des objectifs mesurables et de suivre les progrès grâce à des rapports détaillés qui favorisent la responsabilisation et l'amélioration.
- Allocation des ressources: assure une bonne répartition des efforts de l'équipe pour une planification et un équilibrage de la charge optimaux.
En outre, Axify offre :
- Plusieurs vues de tableau de bord : Personnalisables pour les équipes, les groupes ou l'organisation afin de répondre aux différents besoins.
- Intégration sans code : Connexion transparente avec les outils existants sans frais de développement supplémentaires.
- Coaching personnalisé : Axify fournit des conseils d'experts pour aider les équipes à tirer le meilleur parti de leurs mesures et de leurs processus.
Prêt à optimiser vos performances DevOps ? Réservez dès aujourd'hui une démonstration avec Axify pour découvrir comment accélérer votre processus de livraison de logiciels !



