Software Development
9 minutes reading time


Whether small disruptions or major setbacks, incidents happen, and they can shake up everything you’re working on. But what if each incident became an opportunity to make your processes stronger, your team sharper, and your outcomes better?
That’s what Learning from Incidents (LFI) is all about. You’ll see how to turn chaos into moments of growth. Also, it gives you the tools to prevent future incidents and create a safer, more efficient work environment.
In this article, you’ll learn a step-by-step approach to handling incidents effectively and building a culture of continuous improvement in your organization. Now, let's get straight to it.
Learning from Incidents (LFI) is the process of analyzing incidents to uncover the root causes of the issues that led to them. The goal is to reduce recurrence and improve systems and workflows. Instead of relying on quick fixes, LFI is about moving toward proactive learning by digging deeper into what went wrong and why.
Take the 2024 CrowdStrike-related IT outage as an example. A flawed software update crashed 8.5 million Microsoft Windows systems, disrupting airlines, banks, and public services.
This wasn’t just an IT failure because it revealed gaps in testing and incident response. To prevent such unwanted events, you need to focus on effective learning and building an effective process. Addressing both organizational and human factors helps you create meaningful improvements using LFI.
In the context of LFI, these root causes are extremely varied, and you’ll need to ask yourself these questions to uncover them:
When incidents happen, you have a choice to react or learn.
A systematic review of previous incidents can reveal patterns and insights that help refine your approach to incidents and improve overall safety measures. A strong learning process will help you prevent significant disruptions later on.
Tracking the right incident metrics is key to understanding how your team responds to issues and where improvements can be made. These metrics give you insight into response times, recurring problems, and the efficiency of your processes.
Focusing on these numbers allows you to learn from past incidents, reduce downtime, and build a culture of continuous improvement. Let’s dive into some of the most important metrics to track.
Mean time metrics help you measure how quickly your team identifies, responds to, and resolves incidents. These metrics show where delays happen so you can address them effectively. Here are the key ones you should track:
%20in%20axify%20for%20software%20development%20teams.webp?width=1920&height=1440&name=time%20to%20restore%20service%20(dora%20metrics)%20in%20axify%20for%20software%20development%20teams.webp)
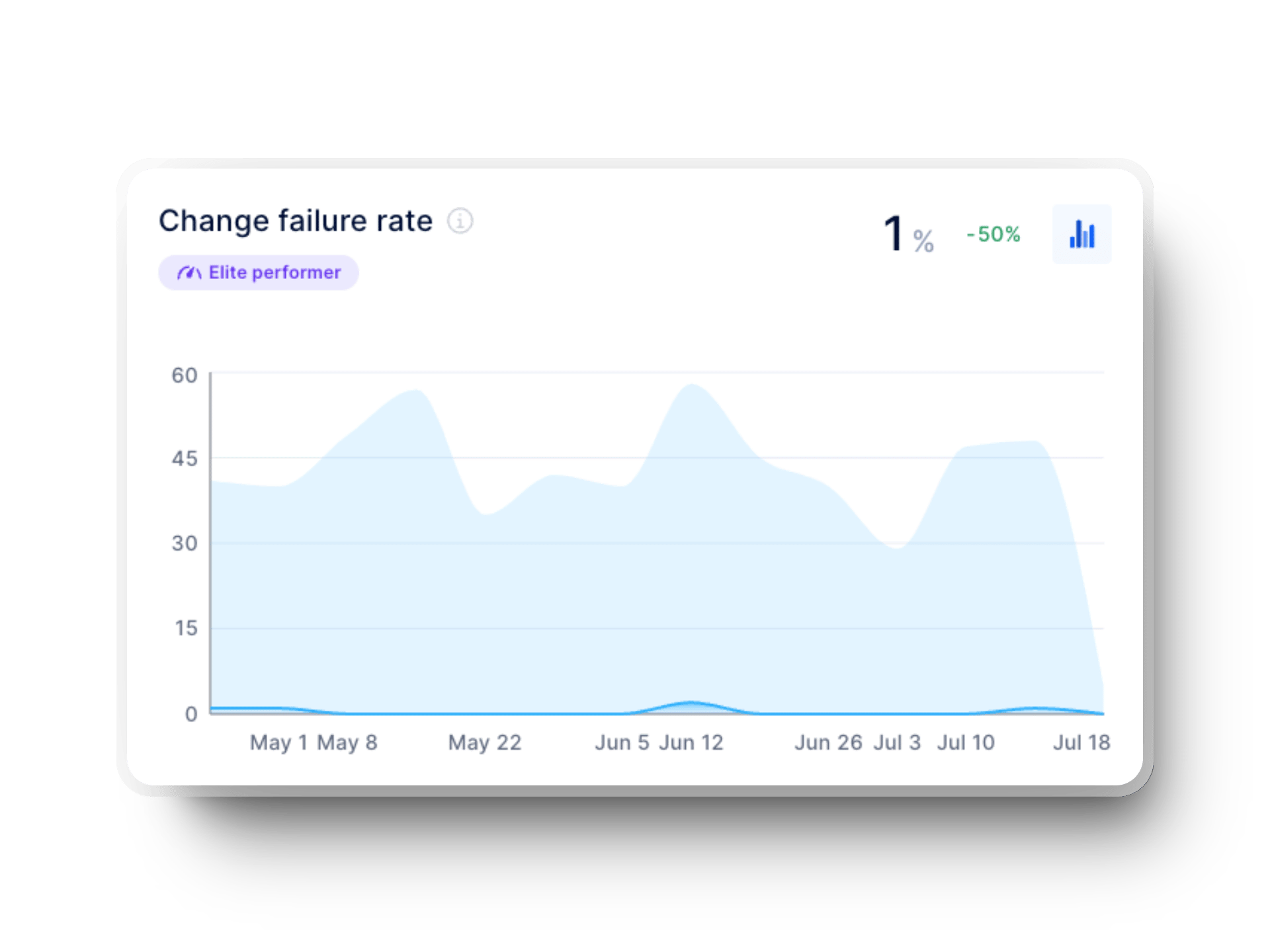
Change Failure Rate (CFR) tells you how many of your team’s deployments lead to failures that require fixing or rolling back. Industry benchmarks show that top-performing teams keep their CFR under 5%. High performers range between 5% and 15%, while low performers can exceed 30%.
If your change failure rate is high, you may have gaps in testing or deployment processes. Lowering your CFR means reducing failure rates and building confidence in your team’s ability to release updates with minimal risk. To optimize this metric, ensure your team learns from incidents and improves their approach to deployments.
Critical defects can disrupt your operations and pose significant risks if left unresolved. A study of 39 production codebases revealed that low-quality code has 15 times more defects than high-quality code. Fixing these defects in low-quality code also takes 124% more time.
Keeping this number low allows you to reduce downtime and maintain smooth operations. Tracking this metric helps you identify trends in defect density and guides your team toward better coding practices and testing.
The number of unresolved bugs in your system gives you an idea of how effectively your team addresses technical debt. For instance, Microsoft’s 47,000 developers generate 30,000 new bugs each month, which shows how quickly bugs can pile up.
If your open bug count is consistently high, it may indicate that your team is overwhelmed or lacking the resources to keep up. Addressing these issues promptly minimizes disruptions and prevents minor bugs from becoming larger incidents.
The longer a bug remains unresolved, the more costly it becomes. Fixing a single bug after a software release can cost up to 100 times more than during development. Delayed fixes can also lead to developer burnout because emergency patches typically require overtime and add unnecessary stress.
Monitoring bug age helps you prioritize issues before they become major problems. It also reflects your team’s ability to manage their workload and avoid underreporting incidents.
The resolution rate measures how many reported issues your team resolves. A high resolution rate shows that your team is proactive and efficient, while a low rate could indicate bottlenecks in your processes.
This metric ties directly into organizational learning by indicating whether your team is applying lessons from past incidents to improve its QA and QC. Finding the root cause of an unsatisfactory resolution rate allows you to identify areas where additional resources or process changes are needed.
Incident metrics measure how well your team responds to, resolves, and learns from incidents. Operational metrics, on the other hand, track the overall performance of your systems, including uptime, reliability, and proactive measures that prevent issues before they occur.
Both types of metrics are essential but serve different purposes. Incident metrics help you assess specific events, such as complex incidents, by identifying contributing factors and improving incident reporting. For example, tracking resolution time and root cause analysis reveals areas for improvement.
Operational metrics take a broader view because they help you focus on positive safety outcomes and system performance to avoid disruptions. Together, they give you a complete picture of your team’s effectiveness in handling incidents and maintaining smooth operations.
When an incident strikes, your team’s response can determine how quickly you recover and learn. Following a structured workflow allows you to reduce downtime, uncover root causes, and build better systems for the future.
Here’s a step-by-step process to handle incidents effectively and foster a culture of continuous improvement.

The first step in incident management is spotting the issue. Quick detection matters because the longer it goes unnoticed, the greater the damage.
Organizations with lower Mean Time to Detect (MTTD) experience 60% fewer data breaches than those with delayed detection. Early detection gives you the time to limit impact and prioritize the response.
Once you detect the issue, escalation is just as important. Promptly notifying the right team members helps ensure the incident is handled by those with the skills to address it. Clear escalation paths prevent confusion and ensure no time is wasted.
Once the incident is identified, you should immediately bring your team together to solve the problem. Swarming is a real-time response technique that skips the traditional tiered escalation model and gathers the most relevant experts to collaborate immediately. This approach works particularly well for complex incidents that involve multiple systems or skill sets.
As described by David Crouch, who co-authored ITIL's "Digital and IT Strategy," swarming allows for quicker decisions and better coordination – in sports, the military, and even in nature. Following the same principles in DevOps, swarming minimizes delays, reduces failed deployment recovery time, and improves customer satisfaction by fostering close communication and knowledge sharing.
According to David Crouch, swarming techniques work best when certain conditions are met. These include close and effective communication, small and flexible teams, shared knowledge, and decentralized decision-making. This approach thrives in IT or other fields when teams are ad hoc, intermittent, and adaptable, allowing for quick, collaborative problem-solving.
Let’s imagine your team is handling a deployment failure that’s caused system downtime. Instead of routing the issue through several support levels, you gather a developer, a system admin, and a team lead in real time.
They brainstorm, test fixes, and deploy a patch (all in one session). This collaborative approach can help you drastically cut recovery times and prevent bottlenecks.
Effective communication in real time (conversations with employees) ensures that the complexity of incidents is addressed and actionable solutions are developed.
Once the team has identified the solution, it’s time to implement it. AI-driven automation tools in IT Service Management (ITSM) can speed up this step. Studies show that automation can reduce incident resolution times by up to 50%.
But resolving the issue isn’t the end. You need to document everything – from what caused the incident to the steps taken to fix it. This documentation creates a knowledge base that your team can reference when similar incidents happen. It also provides valuable input for post-incident reviews and future actions for improvement.
Once the dust settles, it’s time to analyze what happened. A structured post-incident review helps you understand the causal factors, such as what triggered the issue and how it escalated. You should look at human and organizational factors to get a complete picture.
This review isn’t about placing blame – it’s about learning. For example, you can ask questions like:
Use these insights to improve your processes, tools, and team workflows.
Your final step is to ensure everyone benefits from what you’ve learned. Share the findings from the post-incident review with your organization, including frontline employees and leadership.
For example, if a code deployment causes downtime, share a detailed incident alert with your team. Include the root cause, the fix, and remedial actions needed to avoid future failures. This transparency builds trust and ensures continuous improvement.
Linking learnings from incidents to preventive measures helps you reduce the risk of recurrences of accidents and improve overall resilience.
Turning incidents into opportunities for growth requires more than just quick fixes. You need the right strategies to create a culture of continuous improvement and ensure that every incident becomes a stepping stone to stronger systems and smoother operations.
Here are some practical strategies to help your team effectively learn from incidents.
When a major issue arises, bringing the right people together can make all the difference. The Apollo 13 mission is a classic example of the swarming mindset in action.
During the mission, astronauts reported the famous misquote, "Houston, we have a problem," after a serious malfunction. Carbon dioxide levels on board were rising dangerously, and engineers on the ground were tasked with building a makeshift CO2 filter using only the materials available in space. Against all odds, the team collaborated quickly, solved the problem, and saved the crew.
This is what swarming looks like—bringing together the right experts in real time to address complex issues. Swarming is based on communication, decentralized decision-making, and fast action. Adopting this mindset ensures issues are addressed efficiently, even when stakes are high, for your team.
Trusting your developers to deploy fixes directly into production during an incident may sound risky, but it works. This cultural shift creates accountability while speeding up resolution times.
When you allow developers to take ownership, they’re more likely to focus on quality and precision, which reduces the chance of recurring issues. Letting them solve problems in real time helps you avoid delays and create a more agile, responsive team.
After resolving an incident, you should take the time to reflect. Post-incident debriefs are your chance to track metrics related to follow-up actions and dig deeper into root causes. You should also encourage storytelling during these sessions.
Personal narratives from team members typically uncover valuable insights you won’t find in a formal report. This approach humanizes the learning process and helps you capture broader lessons for future prevention.
Every incident affects your bottom line. Improving how you handle incidents allows you to directly impact uptime, customer satisfaction, and operational efficiency.
For example, better incident management can lead to fewer disruptions and faster service restoration, which means happier customers and reduced costs. When you show your team how their efforts contribute to measurable business outcomes, you give them a clear sense of purpose.
Not all incidents deserve the same level of focus. Pouring resources into small, low-impact incidents can dilute your team’s energy and slow progress. Instead, you should prioritize learning efforts on high-impact issues.
These incidents offer the most significant opportunities for improvement and return on investment. Focusing where it matters most allows you to maximize your team’s effectiveness without wasting time or resources.
Selecting the right tools can transform how your team manages and learns from incidents. Whether real-time tracking, effective alerting, or seamless documentation, the right platform can significantly reduce downtime and drive continuous improvement.
Let’s discuss some of the best tools to help you handle incidents efficiently.
Thanks to our real-time visibility into your software development processes, Axify helps you anticipate and address potential issues before they escalate.
It integrates smoothly with your workflows and collects data to analyze key metrics such as failed deployment recovery time, change failure rate, and more. This data-driven approach ensures you’re not just solving problems but learning from them to improve your systems over time.
Besides, Axify’s Value Stream Mapping Tool, which we told you about above, shows you where potential issues impact your SDLC. Seeing these bottlenecks helps you investigate more easily and understand root causes. Based on those causes, you can identify solutions and implement tools where they have the most impact.
Axify gives you real-time visibility before incidents and tracking of post-incident metrics.
Doing so allows you to spot patterns, refine your workflows, and support continuous improvement. Our platform helps teams like yours identify areas for improvement and align their workflows with organizational goals.
PagerDuty specializes in incident alerting to ensure that the right people are notified instantly. By integrating with monitoring tools, it detects anomalies and directs alerts to on-call personnel using customizable schedules and escalation policies.
Its mobile app allows team members to manage incidents from anywhere, which makes it ideal for distributed teams. You can acknowledge and resolve issues in real time and reduce response times even when you’re offsite.
Jira and Confluence offer a powerful combination for incident documentation and follow-up. In Jira, you can log incidents, assign responsibilities, and track progress from start to finish. Confluence complements this as a central hub for documenting post-incident reviews and preventive strategies.
The integration between the two platforms ensures transparency. For example, after resolving an incident, you can document insights in Confluence and link them directly to the Jira ticket. This creates a clear, collaborative approach that ensures lessons learned aren’t lost.
Opsgenie excels at centralizing alerts and ensuring timely responses. It categorizes alerts based on importance and routes them to the right people via multiple channels, such as SMS, emails, and push notifications. If the initial responder doesn’t act, Opsgenie escalates the issue automatically to minimize delays.
The Incident Command Center (ICC) is a standout feature. It combines video conferencing, chat tools, and incident tracking in one place to streamline collaboration during critical events.
Choosing the right tool to enhance your software development process can significantly impact your team's performance. Axify stands out by providing real-time visibility into your team's workflow, gathering actionable metrics from tools you already use, and highlighting opportunities for continuous improvement.
Unlike other platforms, Axify doesn’t just give you data – it helps you understand how your team collaborates and identifies bottlenecks in your delivery process. This allows you to improve workflows, enhance communication, and deliver better software.
If you’re ready to gain clearer insights into your team’s performance and streamline your development processes, Axify is the perfect choice.
Book a demo with us today and see how Axify transforms how your team works!

Learning from incidents is the process of analyzing system failures to identify root causes, improve processes, and prevent similar events in the future. Diving into the aspects of incidents allows you to gain valuable insights into technical and human factors, strengthening your team’s ability to respond better next time.
This approach drives organizational learning and lays the groundwork for continuous workflow improvement.
The five stages of the incident management process are detection, response, resolution, debrief, and prevention. Detection focuses on identifying the incident as early as possible, while response is about immediate action to minimize impact. During resolution, your team works to restore operations.
Debriefing involves analyzing the incident in detail by conducting a comprehensive review approach and sharing lessons learned. Finally, prevention ensures changes are implemented to avoid similar incidents in the future.
You should track metrics such as Mean Time to Detect (MTTD), Mean Time to Recover (MTTR), and change failure rate. These metrics help you measure how quickly issues are identified, resolved, and improved upon.
Axify simplifies this by helping you track essential metrics before and after incidents. It gives you a clear view of your team’s efficiency and enables you to reduce the risk of bad incidents.
Swarming improves incident resolution by enabling faster responses through real-time collaboration with relevant experts. Instead of following a rigid, tiered system, you gather the right people immediately to address the issue. This reduces delays caused by escalations and boosts coordination during incidents.