Software Development
14 minutes reading time


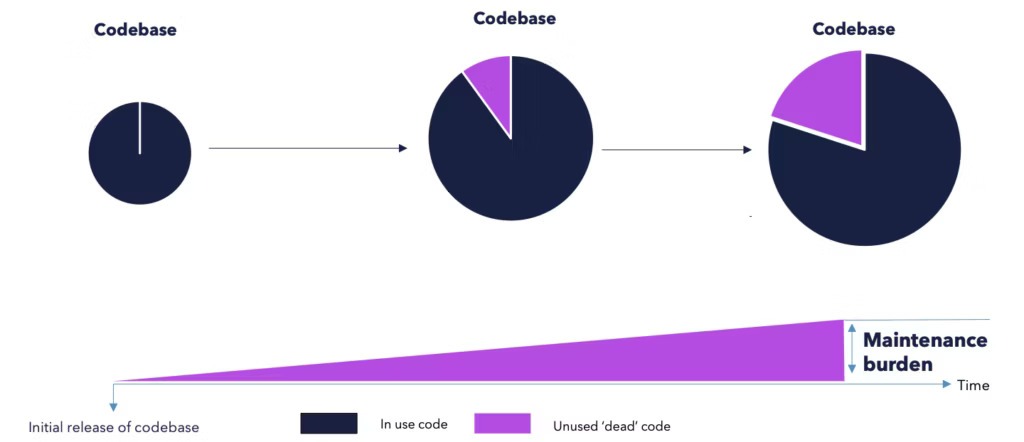
The opening bell rang on August 1, 2012, and within seconds, Knight Capital’s trading platform erupted. Thousands of orders flooded the market, prices swung wildly, and no one understood why. Engineers stared at their dashboards as millions of dollars vanished every minute.
Beneath the chaos lay a single forgotten flag, dormant for eight years, that reactivated an old branch of dead code. It wasn’t supposed to exist. Yet it ran, dragging obsolete logic back into production and costing the company $440 million in roughly 45 minutes before they could stop it.
That's what happens when you leave dead code in your codebase for too long. While this situation can be scary, you don’t have to face that kind of disaster alone.
In this article, you’ll learn how to spot the warning signs of dead code and prevent similar failures in your own software engineering process. But first, let’s discuss what dead code really is.
Dead code is code that still exists in your repository but no longer affects how the program behaves. It compiles, passes tests, and hides in plain sight.
In other words, these are functions that are never called, variables that never change, or branches that no longer connect to the main execution path. Also, you’ll see it in every major programming language. This includes unused imports in Python, inactive methods in Java, or leftover event handlers in JavaScript.
To give you a sense of scale, in a multi-study paper, researchers found that across 35 open-source Java projects, about 15.94% of methods were effectively dead.
Side note: Dead methods are a specific type of dead code; they’re entire functions or methods that are defined but never called.
This is proof that this problem persists even in active systems. That means unused code quietly increases technical debt and weakens long-term maintainability.
Also, here's why you should delete dead code:
Dead code refers to logic that’s unused but still valid to the compiler. In contrast, unreachable code sits beyond a return, throw, or a similar terminating statement.
But here’s the thing.
Dead code can still run if it’s ever reconnected to the control flow, even though no active path calls it right now. Unreachable code, on the other hand, is never executed at all. Execution stops before it, and most compilers flag it as an error or warning during static analysis.
The difference matters because dead code silently survives production. In the 2021 Muzeel study, researchers examined around 40,000 pages and found that the median page had 70% of its JavaScript functions unused. Removing them cuts payloads by up to 60%.
That scale shows how easily inactive code can accumulate unnoticed. It can also impact software performance across complex systems.
Before moving on, you can check out this short clip for a quick visual breakdown:
Next, let’s look at the main types of dead code you’ll likely encounter.
Dead code can appear in subtle ways across your codebase structure. It typically blends into legitimate logic until it starts slowing delivery or increasing architectural debt. Here are the most common types you’ll find and what they reveal about your development process.
Redundant code refers to multiple lines or functions that perform the same task. It usually emerges after parallel development efforts, unmerged experiments, or unclear ownership of modules.
For example, two helper methods might calculate identical outputs in slightly different ways across services. Eventually, this duplication complicates code optimization and inflates maintenance overhead.
To put its scale into perspective, a 2025 paper reported 984 redundant method pairs across 41.17% of analyzed AI-system projects. That level of duplication shows how easily redundancy spreads in growing teams. This is especially true when reviews focus on correctness instead of consolidation.
Obsolete logic is leftover code from old product versions that still exists but is never called. For example, you might find a validation function that was replaced by a new API layer, yet still sits inside your legacy systems. It compiles cleanly, but no longer serves any purpose in production.
Commented-out code is the most visible yet most misleading form of dead logic. Developers typically keep it “just in case” and treat it as a temporary safeguard. But these lines quickly lose context because they can confuse anyone reading the file months later. After a while, they distort code readability and complicate reviews.
For example, a developer might comment out an old API call during migration and forget to remove it. This leaves future reviewers unsure if it’s still needed or safe to delete.
And it happens more frequently than we’d like.
A 2020 study found that in six open-source projects, up to 20% of commits included commented-out code during early development. That number shows how common it is for teams under delivery pressure to comment instead of clean.
Empty if, while, or for blocks are small but costly. They typically result from rapid iteration, where developers stub logic for future use and never return. For instance, a developer might leave an empty if (error) block after debugging and forget to fill or remove it, which can add noise to the control flow.
These placeholders clutter execution paths and inflate cyclomatic complexity, especially in data-heavy or event-driven modules. While static analyzers can flag them, their persistence usually reflects gaps in review focus or incomplete backlog grooming. Removing them improves flow clarity and compiler efficiency.
Default cases that never trigger look harmless but quietly add maintenance overhead. Teams tend to add them as safety nets and forget to update or remove them when business logic changes.
For example, a default: block might handle an “unknown” user type that no longer exists after a schema update. Well, this can mislead future maintainers about valid states and add unnecessary complexity to the logic flow.
Next, let’s look at what causes these fragments to appear in the first place.
Dead code accumulates when changes in your software development process outpace cleanup and ownership. It builds up gradually as teams move fast, refactor code, or experiment without tracking what’s left behind.
Here are the most common causes you’ll recognize in your projects.
Each of these patterns signals friction in your delivery flow. Moving on, let’s see what that friction costs your teams.
Dead code adds invisible weight to your system. It doesn’t break builds, but it quietly slows progress, inflates complexity, and increases long-term delivery risk. These are the main consequences you’ll see in your projects.
Dead code increases system complexity and makes every change harder to predict. It’s estimated that 20-40% of ICT companies’ technical estates consist of technical debt. This means a large part of what’s maintained adds no business value. In the long run, that extra weight delays releases and expands maintenance costs.
Unused functions and old logic confuse new developers, especially during onboarding or debugging. It takes longer to trace dependencies, and that raises the risk of regression when modifying active modules.
Unnecessary code extends compile and test cycles. According to Azul Systems, larger applications showed that nearly 20% of code, and in some cases up to 66%, was unused. That bloat directly slows build and test pipelines, which increases feedback time and lengthens iteration cycles.
Dead code can hide outdated dependencies or unchecked inputs. This can expose your system to avoidable security vulnerabilities. Even a single unpatched function can reintroduce exploitable behavior long after it was thought to be removed.
Dead code misleads linters and IDEs. This makes static analysis results less reliable and increases false positives during reviews. It also wastes reviewer time by surfacing warnings that don’t reflect the actual production path.
Next, let’s discuss how to detect this hidden drag before it impacts your performance and delivery.
Finding dead code requires combining automated detection with contextual awareness of how your team ships and maintains software. No tool can find all dead code, though static analysis tools can find some of it. That’s because inactive logic usually hides behind business rules, feature flags, or outdated dependencies.
The best approach uses data, review discipline, and historical insight together. Here are the most effective ways to uncover it.
You can start with automated detection through static analysis tools like SonarQube, ESLint, Pyflakes, or Pylint. These tools analyze source files without executing them. They also flag unused imports, variables, and unreachable branches.
Next, configure rulesets based on your language and project maturity. Teams working in large microservice environments usually benefit from stricter thresholds for unused parameters or ignored exceptions.
It also helps to automate scans in CI pipelines so that issues appear before merge.
However, static analysis only finds syntactic signs of dead code.
They catch obvious unused elements (imports, variables, unreachable code), but can’t find contextual dead code (like code hidden behind feature flags or rarely triggered conditions). They also can’t find logic that’s technically valid but functionally obsolete.
That’s where deeper validation is needed.
Test coverage is one of the most practical signals of inactive paths. You can identify functions or classes that are never executed by comparing runtime coverage data from unit, integration, and system tests.
For example, if a file’s coverage consistently remains at 0% across multiple sprints, it’s a strong indicator that the code may be unused or outdated, though manual verification is needed.
After all, some low-level utilities, fallback logic, or rarely used error handlers might not be covered in tests but still execute occasionally in production.
Combine coverage gaps data with Axify metrics like PR cycle time, WIP, and throughput.
These flow metrics measure how fast teams deliver, not how much code is active or unused. Still, you can visualize correlations (e.g., long PR cycles might lead to stale branches, which signals a potential dead code).
In other words, you can see where inactive code accumulates or branches linger unmerged.
![]()
Of course, you should treat coverage as a signal rather than confirmation. Some modules might be intentionally excluded from tests, so human judgment is important before removal.
No tool replaces a thoughtful code review. During review sessions or planned refactor sprints, encourage developers to trace function references. They should verify whether those methods are still invoked by active endpoints or workflows.
Look for code paths wrapped in obsolete feature toggles or methods imported but never called. A quick way to spot patterns is by reviewing diffs where files change frequently, but specific functions don’t.
This typically hints at code that’s no longer in use. Pairing this manual audit with your delivery data (for example, Axify’s metrics on work-in-progress or PR cycle time) helps you see where stagnation starts to appear. Basically, you can spot where long-lived branches or stalled reviews allow inactive code to build up.
%20in%20Axify.webp?width=1920&height=1440&name=work%20in%20progress%20(WIP)%20in%20Axify.webp)
Modern IDEs like IntelliJ IDEA, VS Code, and Eclipse include built-in analyzers that detect unused declarations in real time. These suggestions are particularly effective during active editing since they show issues contextually.
Developers can hover over warnings to confirm whether the element is safe to delete or requires review. For enterprise repositories with multiple owners, combining these insights with your IDE’s dependency mapping view can expose unreferenced packages or orphaned components.
Your Git repository holds behavioral evidence of dead code accumulation. So, you should look for files or functions that have not been touched for long periods. Six months or more is a common threshold for review.
Next, you can script this with git log --follow or visualization tools like GitLens to track edit frequency by file or method. Once you have that view, correlate that data with recent deployments to identify components that haven’t contributed to production builds.
Stale paths usually appear in modules with low commit velocity but high complexity. This indicates work that’s been abandoned rather than updated.
Now, we'll need to see how to remove dead code safely without disrupting production stability.
Fixing dead code means restoring clarity, improving performance, and preventing regressions. The right approach combines automation, team alignment, and safe rollback strategies. Here are the most effective ways to clean up dead code with precision.
Start by identifying sections you can safely remove using verified test coverage. If your unit or integration tests consistently bypass certain functions, they’re strong candidates for deletion. You can also cross-check coverage reports over multiple sprints to ensure the code hasn’t been reintroduced through merges or feature toggles.
Real-world data proves why this matters.
A study on 30 mobile web apps showed that removing dead methods reduced transferred bytes and improved load time. One subsystem had 25% of its methods inactive before cleanup. So we can safely conclude that systematic deletion can directly improve runtime efficiency and maintainability in other cases, too.
When removing code, run your test suite after every deletion batch. If any dependent modules fail, it signals an unintentional coupling that needs decoupling first.
Version control is your safety net. So, always isolate deletions in separate branches and connect them to cleanup tasks or tickets. When dealing with larger systems, use feature flags to disable rather than delete from the get-go.
This allows testing in production-like environments before full removal. If unexpected dependencies surface, rollback is straightforward.
Large, high-performing companies implement this kind of practice consistently.
For example, Meta Platforms’s large-scale cleanup initiative “SCARF” removed over 104 million lines of code and petabytes of unused data, saving over one megawatt of compute power.
This is proof that even global systems can prune safely when versioning and rollback strategies are part of the workflow.
While you may not be deleting at that scale, the principle remains the same. You need to use your tooling to make reversibility easy.
Not all unused code is obsolete. Some functions may support rarely triggered conditions or serve as fallbacks. Before deleting large or interconnected modules, validate intent with the original author or product owner.
Side note: In some cases, you can’t do that: in large, long-lived systems where the “original author” left years ago or in open-source or multi-team projects where ownership is diffuse. So in these situations, you can verify the purpose with your team or review commit history before removal.
Reviewing the purpose ensures you’re not removing behavior that’s just dormant under specific runtime conditions. This is especially important for modules handling errors, payments, or failovers (logic that doesn’t run frequently but is still critical).
To make this efficient, create a shared “cleanup checklist” within your team’s workflow. When everyone follows the same criteria for identifying and confirming dead code, you reduce the chance of removing something important.
Plan cleanup deliberately. Instead of waiting for downtime, schedule recurring “refactor sprints” where developers focus on reducing inactive code. Include cleanup as part of sprint objectives so it’s tracked and visible.
Some of Axify’s metrics, such as PR cycle time or flow efficiency, help you measure the effect of these cleanups. Shorter cycles and more consistent flow typically follow after teams reduce stale branches and redundant logic.

You can also assign cleanup by repository area to promote ownership. For instance, one team handles backend APIs, another focuses on front-end components. This prevents unowned regions of the codebase from accumulating dead paths.
Modern IDEs like IntelliJ IDEA, VS Code, or Rider can detect unused imports, unreferenced methods, or redundant variables in real time. These automated insights are particularly useful when working in large files or polyglot codebases.
You can configure the inspection settings to your team’s standards so warnings reflect your actual production rules rather than default thresholds. Also, when performing mass cleanups, always re-run inspections after merging feature branches. This helps prevent reintroduction of previously deleted logic through concurrent work.
Sometimes dead code hides within unnecessary abstractions. To avoid this, apply structural refactoring patterns to simplify the codebase:
These techniques make your architecture leaner and reduce confusion during future refactors. Simplifying hierarchies cuts maintenance costs but also lowers the mental load during onboarding or audits.
Finally, eliminate leftover assets. This includes old configuration files, scripts, or libraries that no longer contribute to production builds.
Check for unreferenced dependencies in your package manager or CI configuration. Removing these shrinks the repository size, shortens build times, and reduces cognitive noise.
Preventing dead code requires building habits and systems that keep your codebase healthy over time. The goal is designing a development process that makes unnecessary code less likely to appear in the first place.
These are the practical habits that help you maintain cleaner, more reliable systems:
Dead code is a reflection of how work flows through your system.
Every unused branch or stale method points to hidden inefficiencies like high WIP, long PR cycles, or incomplete cleanup. Tightening your delivery habits helps you prevent this silent drift before it compounds into technical debt.
Axify doesn’t remove dead code directly, but its DORA metrics, PR insights, and Value Stream Mapping tool highlight conditions that correlate with quality problems (slow reviews, growing WIP, or unmerged branches). It can also indicate phases of your project where dead code may be affecting your flow, and the impact of your fixes.
More importantly, our team can help you apply the practices that stop dead code at its source. This includes smaller batches, reduced WIP, and stronger review cadence.
Book a demo with Axify to strengthen visibility and sustain cleaner engineering flow.
