Delivery Performance
7 minutes reading time

.webp?width=1200&name=Axify%20blogue%20header%20(9).webp)
Your code is ready. The tests pass, and the feature works – but the deployment? That’s where things slow down. Delays, approvals, and bottlenecks turn a simple release into a long waiting period.
This all comes down to deployment time, which tells how long it takes to push code from development to production. A slow process means missed opportunities, while a fast, reliable one keeps your team moving.
So, what exactly is this metric, why does it matter, and how can you speed it up without sacrificing stability? This guide breaks it all down. Let’s get started.
Deployment time is the duration between merging a pull request (PR) and when the changes are successfully deployed to production environments.
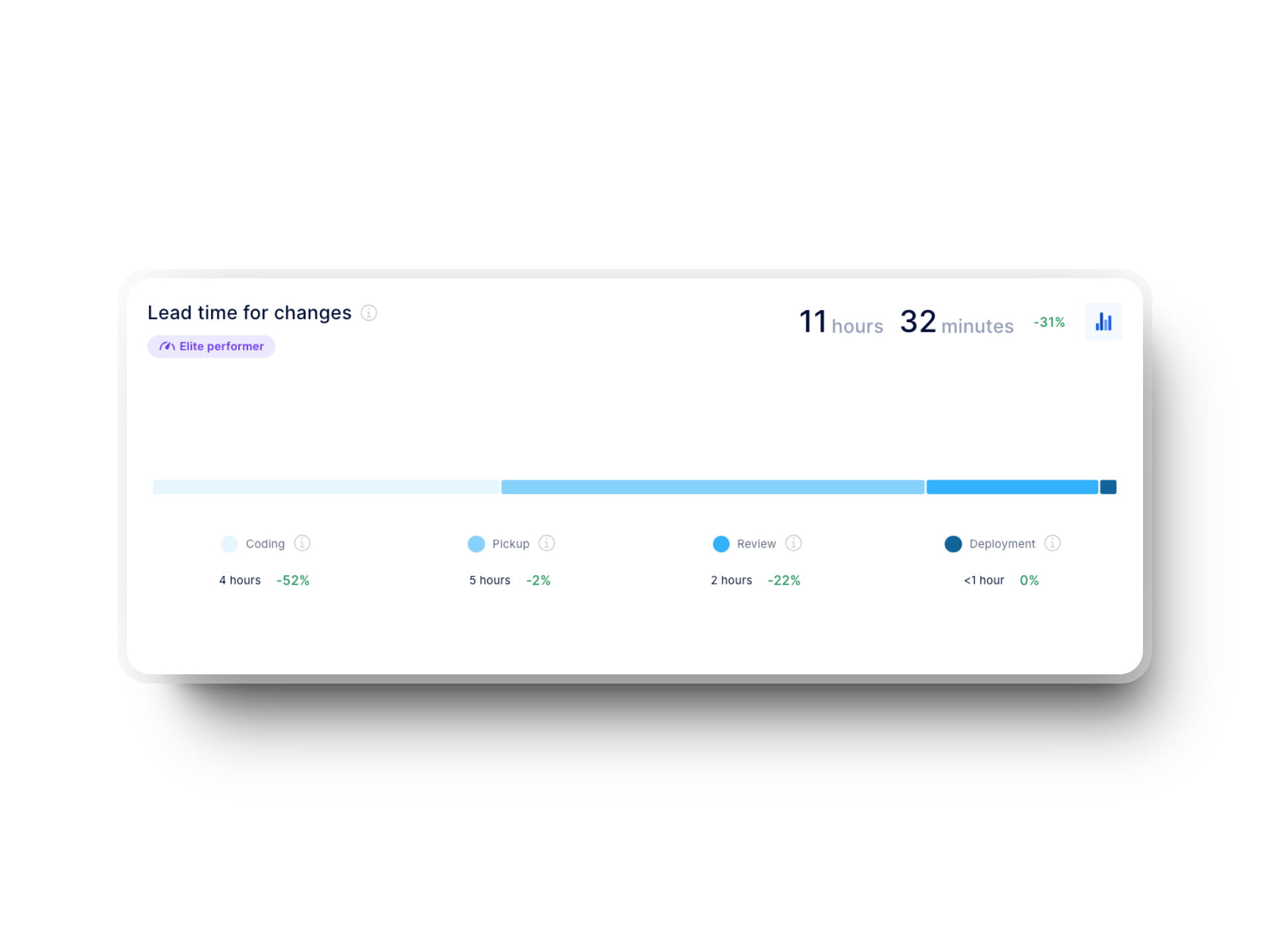
This metric tracks just one part of the bigger software development lifecycle. Still, shorter deployment time is crucial in efficiently getting changes from development to users. This metric is treated as a subset of lead time for changes, which is broken down into four key stages:
You may also wonder what a good deployment time is.
While there aren’t any reliable benchmarks, we can check out the DevOps Research and Assessment (DORA) 2024 report. Since deployment time is a subset of lead time for changes, we can look at what’s expected from organizations from that point of view:
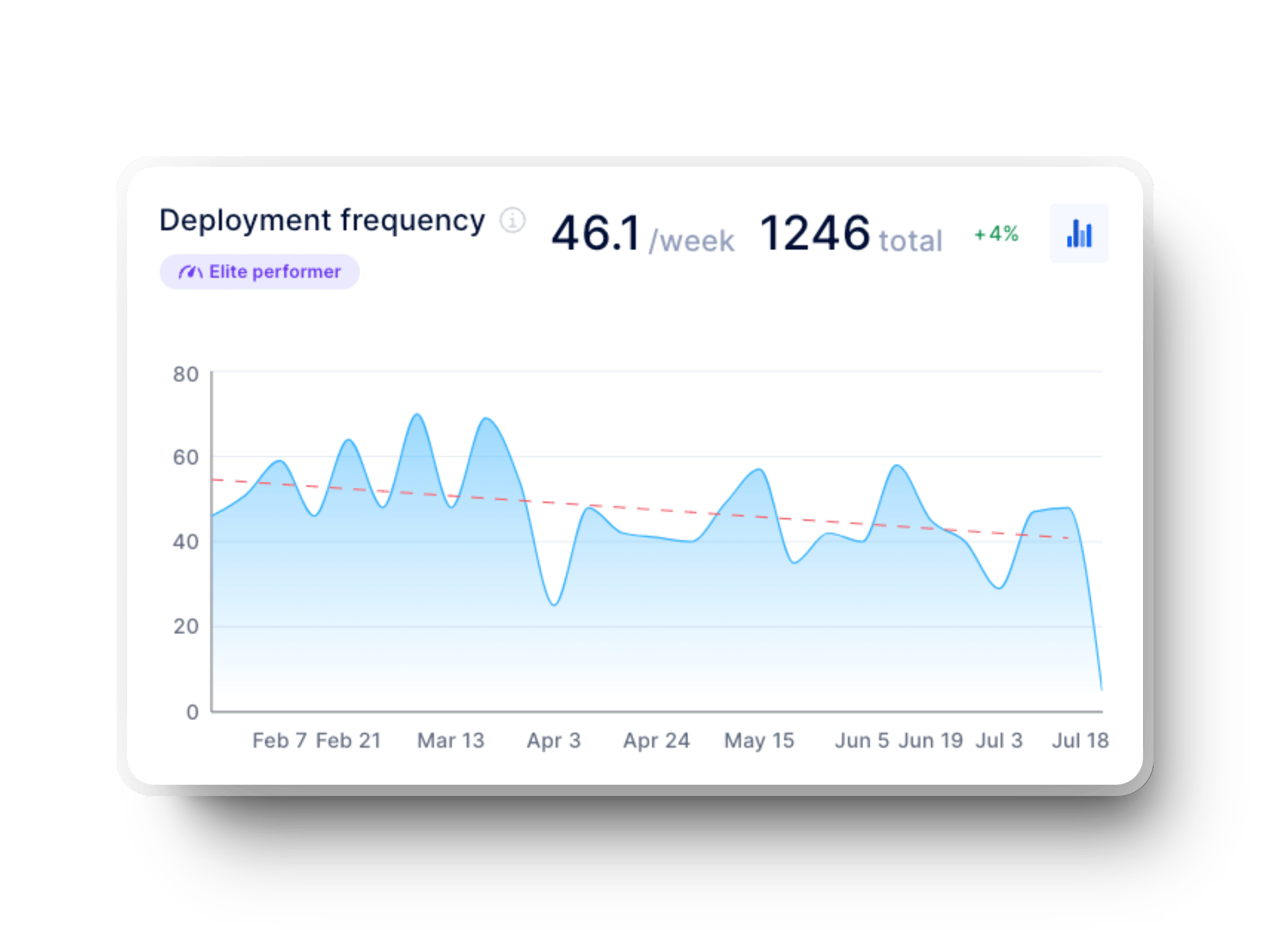
Similarly, a good deployment frequency for Elite performers is on-demand or multiple times per day. That brings us to the next point:
Deployment time is the time required to deploy a change once it's ready, while deployment frequency is the frequency with which your code hits production.
The two are closely connected.
If your deployments are slow, frequent updates are nearly impossible. Improving deployment time is the key here, as it allows you to release more consistently and keep code moving.
Now that you know how deployment time differs from deployment frequency, it’s time to understand why tracking this metric matters. It brings in benefits like:
Why should you focus on improving deployment time? Let’s break down the key reasons that make it a game-changer for your team and your software:
Improving deployment time comes with many benefits, but it’s equally important to understand that a few things could be slowing it down without you even realizing it, such as:
Deployment time measurement tracks how long it takes for code to go from “Merged” to “Live.” In Axify, this starts when a pull request (PR) is merged and stops when the change is fully deployed in production environments.
Deployment time is typically measured in seconds, minutes, or hours. For example, a team’s deployment time is 300 minutes or 5 hours.
Tracking deployment time is great, but it doesn’t tell the whole story. To really understand DevOps performance, here are a few more metrics worth keeping an eye on:
%20in%20axify%20for%20software%20development%20teams.webp?width=1920&height=1440&name=time%20to%20restore%20service%20(dora%20metrics)%20in%20axify%20for%20software%20development%20teams.webp)
Ever wondered how top-performing DevOps teams keep releasing every day? It’s not magic. It is all about optimizing deployment time by using the right strategies. And we’ll analyze the best ones below:

If your Continuous Integration and Continuous Deployment (CI/CD) pipeline takes forever, unnecessary approvals, redundant tests, or inefficient scripts may be creating bottlenecks. Identifying and streamlining these steps can significantly speed up deployments.
But how do you figure out where the bottleneck is?
Check your key metrics, such as time to deployment, change failure rate, and the number of times per day you ship code. If your team spends more time waiting on approvals or rerunning unnecessary steps than actually deploying, it’s time to clean up the process.
What you can do:
If your pipeline runs tests one by one, you're wasting time. Distributed computing addresses this by running tasks in parallel.
For example, a test suite that takes 30 minutes to complete on a single machine can be split across five machines using tools like Buildkite or GitHub Actions. Each machine runs a portion of the tests simultaneously, reducing the total time to just 6 minutes.
The result?
Quicker deployments, faster feedback, and fewer delays.
If your infrastructure can’t keep up with demand, deployments slow down.
Too much traffic? Servers struggle.
Low traffic? Resources sit idle and burn costs.
Neither is ideal.
Auto-scaling options like AWS Auto Scaling, Kubernetes Horizontal Pod Autoscaler, and Google Cloud Managed Instance Groups can instead scale up or down based on real-time demand.
Serverless options such as AWS Lambda or Google Cloud Functions take it further—there are no servers to manage; you can just deploy and go.
The longer code stays separate, the more complex it gets to merge, test, and deploy without introducing problems. Trunk-based development keeps things moving by merging small changes directly into the main branch multiple times daily.
For example, instead of working on a new checkout button in a separate branch for weeks, you can break it into smaller updates and merge continuously:
Manually deploying code is slow, error-prone, and a waste of time: the more manual processes involved, the higher the change failure rate.
Deployment automation takes care of everything, including versioning, testing, rollbacks, and releases, without requiring constant human input. You can use tools like Spinnaker, ArgoCD, and GitHub Actions to streamline this, so deployments are always smooth, fast, and reliable.
When deployments slow down or fail too often, guessing won’t fix the problem. You need data. With DevOps dashboards, tools like Axify deliver real-time insights into application performance by tracking key metrics such as:
Big releases are a gamble. Ship too much at once, and you’re stuck debugging a giant mess when something breaks.
Smaller changes are much safer and quicker to deploy.
For instance, when migrating a database, instead of making a massive schema change all at once, you can:
If something fails, rolling back is easy, and there’s no impact on users.
Are you frequently catching bugs right before deployment?
That’s a nightmare. Fixing them so late disrupts workflows and turns deployments into chaos. Plus, it costs up to 30 times more. You can avoid this by implementing shift-left testing that moves automated testing earlier in the software development process so problems get caught before they escalate.
Combining shift-left on QA with other approaches, Axify helped BDC Canada reduce its product delivery by up to 51%. As the issues were detected and fixed earlier in the pipeline, the deployment time was reduced, allowing faster and more efficient releases.
If a team has to jump through hoops for every little change, deployments slow down to crawl. Too many approvals and too much red tape kill momentum.
Your team needs the freedom to ship updates without waiting for management to say yes every time. If automated testing and key metrics show a release is good to go, why hold it back?
Ever had code that runs perfectly in staging but crashes in production?
This happens when environments don’t match. Data parity prevents this and keeps development, staging, and production as consistent as possible.
Say you're working on a payment processing system. If staging only has mock transactions, you might miss real-world edge cases. But with properly masked live data, you catch issues before they hit production, which leads to quicker deployments and fewer surprises.
Deployment and release are not the same. Just because code is deployed doesn’t mean it has to go live immediately. Frequent deployments keep the system in a releasable state, but the actual release should happen when it makes sense for the business.
Feature flags make this possible. You can deploy frequently to keep updates ready in production while giving product managers control over when to release.
One example includes deploying a new checkout flow behind a feature flag and keeping it inactive until the business is ready. When the time comes, you can flip the switch with no extra deployments or delays—just a fast, low-risk release.
Deploying straight to production can be risky. If something breaks, rolling back takes time, and downtime hurts users and the business. Blue/green deployments solve this by keeping two environments: one live (blue) and one idle (green).
When a new update is ready, it’s deployed to the green environment while users continue using blue. Once everything checks out, traffic is switched to green instantly. If something goes wrong, rolling back is just as fast.
In this guide, we’ve explored the crucial role deployment time plays in the SDLC and why speeding it up can lead to better productivity, faster feedback loops, and more reliable releases.
If you’re serious about cutting deployment time, Axify can help with features like:
VISUEL HS : Axify value stream mapping-1 Alt tag: Axify VSM
VISUEL HS : Axify DORA metrics dashboard 4 key metrics Alt tag: DORA metrics dashboard
VISUEL HS : software delivery forecast-1 Alt tag: Delivery forecasting by Axify
Let’s work together to transform your release pipeline. Book a demo with Axify now!
