Delivery Performance
9 minutes reading time

%20(1).webp?width=1200&name=Axify%20blogue%20header%20(13)%20(1).webp)
Modern product organizations often talk about developer velocity, but the term is usually reduced to a single planning proxy, such as story points or sprint throughput. Those proxies break down as systems scale, because they describe effort rather than how work actually moves through the software development process.
That gap becomes visible when work is marked as “done” but releases still slow down, queues build up between stages, and software delivery timelines become unpredictable. In those situations, teams lack a system-level way to explain where time is actually being spent and which constraints are limiting throughput.
This article proposes a different approach.
Instead of using story points or subjective estimates, it defines velocity in terms of observable movement through the delivery system. The goal is to give teams a way to reason about velocity using real flow signals, real constraints, and real delivery outcomes.
You’ll see how to frame, compare, and evaluate velocity in a way that supports planning and executive decision-making without turning velocity into a proxy for individual effort.
So, let's get started!
In Agile delivery, velocity can be understood as the rate at which work moves from commitment to completion over time. In this sense, “movement” refers to observable state transitions rather than estimated effort. In practice, this movement spans intake, development, review, and release.
It's observed at the system level rather than through individual effort. That means velocity is derived from how work progresses through shared stages, not from how much any single person produces. That framing matters because software development velocity reflects how reliably teams turn planned work into usable outcomes across Agile frameworks.
From that, we understand that velocity reflects delivery behavior as it emerges from queues, handoffs, rework, and dependencies, rather than standing as a single metric on its own. That’s why velocity can inform planning and forecasting discussions, but it cannot be used alone to rate team performance.
Its value comes from showing how changes in workload, dependencies, or bottlenecks affect delivery speed.
You can check out this video to learn more about the standard definition of velocity:
Next, let's see why we can't reduce developer velocity to a single metric.
When leaders ask for “velocity,” they often want one number. But one number cannot explain the constraints that slow work down under real operating conditions. In practice, pressure from leadership typically pushes discussions toward simple proxy metrics like story points per sprint or throughput.
However, that simplicity removes the context needed to explain where time is being spent and which constraints are slowing delivery as systems scale. As a result, decisions get made on partial signals instead of how the delivery system is actually behaving.
More importantly, we believe that velocity emerges from how the system works as a whole. It does not come from individual effort alone. Across developer teams, outcomes depend on handoffs, dependencies, review paths, and release coordination that shape flow long before code reaches production.
That is why Axify treats the system as greater than any individual contributor.
Software delivery is a team sport: outcomes are shaped by shared processes, coordination costs, and cross-role dependencies. Metrics that focus too heavily on individuals tend to hide these system-level effects.
As Alexandre Walsh puts it:
Seen another way, metrics only become useful when they can be operationalized in a specific delivery context. A multiple-case study of Agile organizations found that teams were interested in assessing process aspects like velocity, testing performance, and estimation accuracy, but often struggled to turn these into actionable inputs. The main challenges were data availability, tooling constraints, and uncertainty about whether the chosen metrics actually supported real decision-making.
That finding supports a core Axify belief: metrics are only useful when they’re interpreted in context, not when they’re treated as theoretically perfect.
So, frameworks matter more than KPIs.
If metrics only make sense when interpreted in context, you need a way to relate metrics to real system behavior.
A framework connects signals across the system, surfaces where flow breaks down, and explains the tradeoffs leaders face without turning velocity into a scorecard.
Story points fit as a planning aid rather than as a way to measure velocity in software development.
In sprint planning, story points help frame uncertainty, support capacity conversations, and align software developers on relative effort within a single team. We already covered this in a previous article on story points. In those narrow cases, they can support planning without claiming to explain delivery speed.
However, problems start once story points are used beyond that context. At that point, planning signals turn into proxies for system performance.
As explained in our earlier work on development velocity, story points say nothing about:
At Axify, we believe this is because story points ignore wait states, rework, and handoffs, which account for most real delivery time.
Throughput-based signals offer a clearer alternative.
They reflect completed work flowing through the system, and are shaped by builds and tests, review paths, and release mechanics. That distinction matters because velocity emerges from system behavior under real constraints, not from estimation artifacts or individual effort.
Moving on, we'll show you how to calculate velocity in Agile software development.
Velocity becomes hard to explain the moment leadership asks for one number and delivery reality refuses to line up with that simplification. That tension usually surfaces during planning reviews, release discussions, or post-incident conversations, when a reported velocity no longer matches actual release timelines, growing queues, or missed delivery targets.
In response to that pressure, the Axify Developer Velocity Framework provides a concrete way to reason about velocity. It gives you a structure that stays defensible under scrutiny, because velocity is treated as measurable system behavior.
More specifically, the framework measures velocity across three complementary dimensions that show how fast work moves, how often value reaches production, and how reliably completed work holds up over time.
Flow velocity answers a direct question: where does work slow down once it enters the delivery system? At this level, velocity is defined as movement through the delivery system and is independent of estimation units or planning artifacts.
What matters is how long work spends waiting, moving, or looping back between states, across queues, reviews, and releases. This makes flow a property of the system rather than of individual effort. Here are the metrics you need:
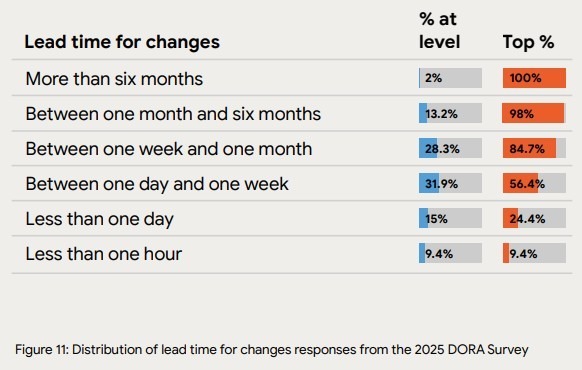
Once bottlenecks form, adding more effort does not meaningfully increase delivery speed. That’s because congestion at handoffs and queues blocks execution.
Delivery velocity shifts focus to how reliably finished work reaches production and becomes usable. This dimension typically explains why work can appear “done” in internal states (merged, tested, approved) while user-visible outcomes lag behind because releases to production are infrequent or delayed.
You need to track these metrics:
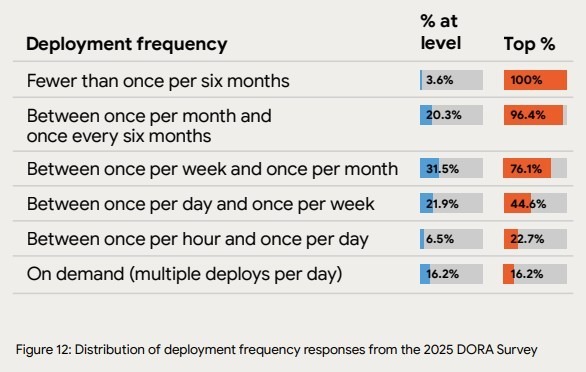
At this level, delivery velocity reflects organizational release capability. Keep in mind that it doesn't reflect individual output. That’s because organizational-level release mechanics (pipelines, controls, and coordination paths) determine how often value reaches users.
Sustainable velocity addresses what happens to delivery speed when systems face incidents, regressions, and production failures. Team-level velocity drops once regressions, incidents, and rework start to accumulate.
This dimension in our framework measures whether velocity holds during incidents, regressions, and release fallout.
Here are the important metrics you need:
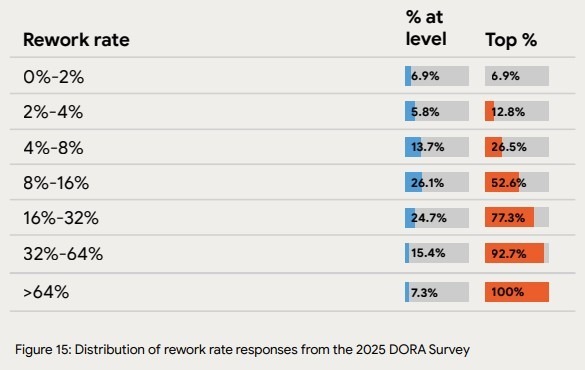

Velocity that creates instability does not hold. When failure rates, rework, and recovery effort rise, they cancel out gains made elsewhere. Time shifts from delivery to remediation, which reduces net throughput and delays user-visible outcomes. As a result, it damages your business performance.
Consistency matters when velocity is discussed across teams, yet micromanagement breaks trust and distorts behavior. That tension usually surfaces during planning reviews and executive conversations, when leaders want comparable signals across teams, but delivery systems differ in structure, risk, and constraints.
So, measurement needs structure without turning metrics into controls. The Axify approach addresses that tension by focusing on system-level patterns and relationships instead of individual output.
Here are the best practices that keep velocity explainable and stable at scale.
Velocity becomes meaningful once trends are observed within the same team over time. Looking at direction instead of point-in-time values keeps attention on delivery system behavior rather than short-term variance. This is where workflow analysis helps explain whether an intervention reduced friction or simply moved delays downstream.
This is also where teams usually get stuck.
To address this gap, Axify is introducing AI-powered, actionable insights directly into the platform.
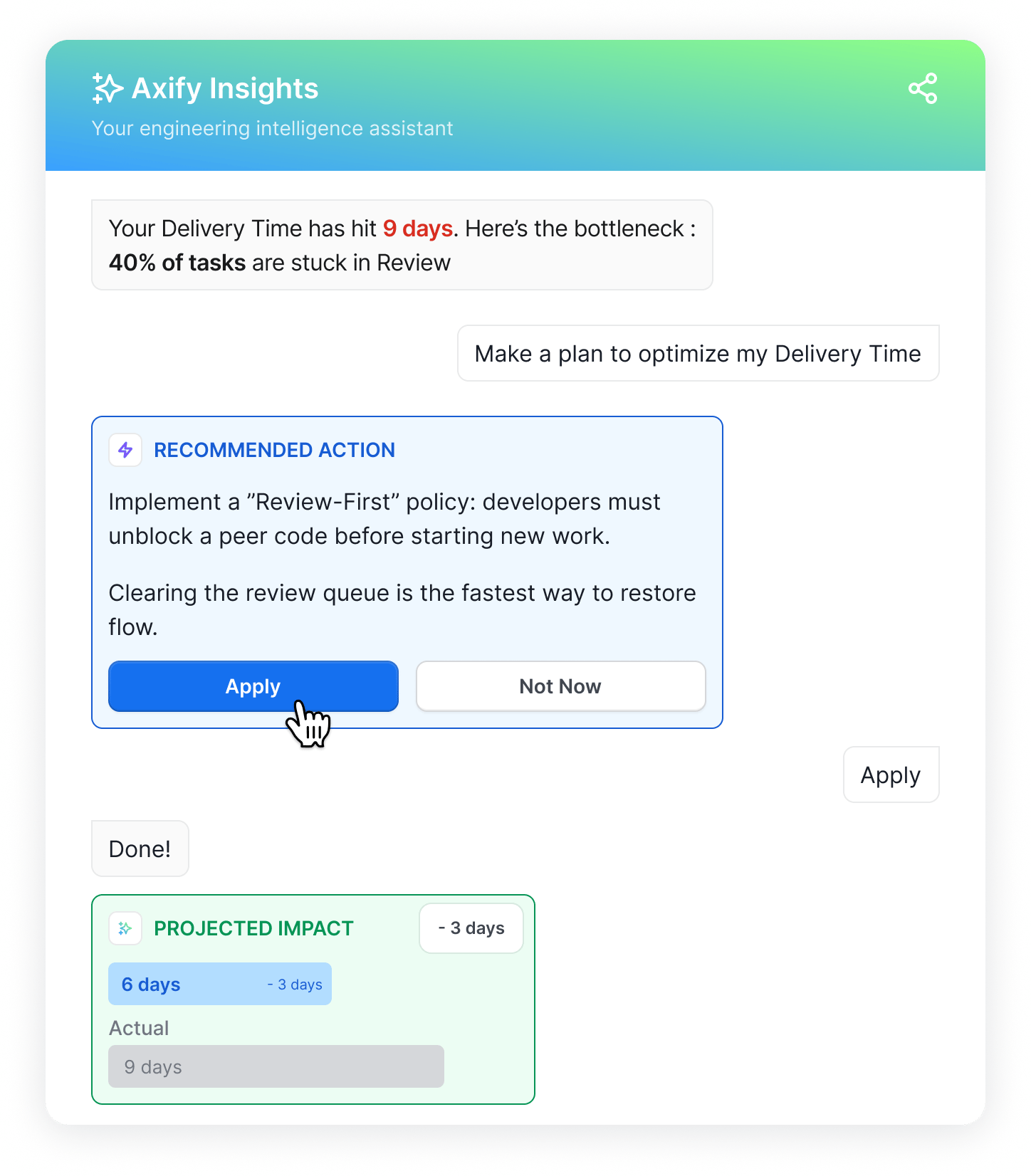
Teams can ask questions in plain language, explore what’s happening across their delivery process, and receive system-level recommendations.
Ready to move from measurement to action? Start your free trial or book a demo.
We think that aggregation should happen at the dimension level. This means flow, delivery, and sustainability signals can be summarized across teams without forcing false equivalence (i.e., a single definition of “fast.”). That structure supports leadership visibility during portfolio reviews while preserving local context. This keeps comparisons accurate, prevents misinterpretations, and protects developer experience.
Baselines anchor conversations in reality. Comparing current signals against a known baseline shows whether changes actually reduce friction or simply shift delays between stages, teams, or release phases. Over time, this practice builds credibility because leaders can connect actions to outcomes even as teams, tooling, or scope change.
Comparison only works when teams are compared along the same dimensions rather than against identical targets. Different teams are constrained by different parts of the system. Flow issues in one group may point to review paths, while delivery gaps elsewhere may reflect release mechanics.
Framing comparison this way keeps conversations focused on constraints and system behavior instead of ranking teams by speed. It also supports shared learning across the organization.
Improvements in one area typically create regressions elsewhere. From our experience, faster flow without delivery readiness increases queues before release. Likewise, faster delivery without sustainability increases rework and slows recovery after change.
In other words, changes in one part of the system almost always affect other parts. That’s why Axify treats velocity as a system-wide behavior, not a single performance metric.
So, let's see how to increase developer velocity using the Axify framework next.
Velocity improves only when system constraints are addressed directly. When pressure rises, pushing harder without changing the system usually shifts waiting and rework to another stage.
So, the Axify framework helps you focus on the constraints that actually limit delivery, rather than shifting delays from one stage to another.
Here are the core ways to increase velocity across flow, delivery, and sustainability using our framework.
Flow slows when queues and idle time grow. In most organizations, that idle time accumulates in review queues, test environments, and dependency handoffs. Reducing wait states starts with making queues visible and treating them as system design problems.
Limiting work in progress follows naturally. When too much work moves through the system at once, attention fragments and completion slows because queues lengthen at handoffs.
Smaller batches reduce contention and make delays easier to trace back to a specific step. Shorter feedback loops reinforce this effect. Faster signals from tests, reviews, or integrations surface failures earlier, before work accumulates downstream.
At this level, velocity improves because the system spends less time idle at queues and handoffs.
Delivery velocity slows when ready-to-ship, completed work waits in pre-production states. Large release batches create artificial waiting, increase coordination overhead, and raise the cost of rollback. Smaller, more frequent releases reduce that risk and keep progress visible to both teams and stakeholders.
In our experience, deployment regularity matters more than raw frequency. Predictable release patterns allow teams to plan around production changes and reduce last-minute escalation during critical windows.
In fact, predictable release cycles expose friction because problems stop being dismissed as “one-offs.” When releases are irregular, delays get blamed on timing, environment issues look accidental, and rollback pain feels situational. But with a consistent cadence, the same failures repeat in the same places, making bottlenecks visible and, therefore, fixable.
As a result, velocity increases because work reaches production more consistently.
Speed that triggers incidents slows future delivery. Sustainable velocity depends on whether the system can absorb change without creating repeated failures. Tracking rework patterns shows where requirements were unclear, validation happened too late, or changes were merged before they were production-ready.
Review quality also plays a role. Superficial or delayed reviews that degrade feedback quality allow issues to reach production. Here, recovery costs multiply across teams and releases.
Improving review clarity and ownership reduces both rework and downstream disruption. When failures do occur, recovery speed becomes critical. Faster detection and resolution limit follow-up work and keep the system stable under pressure during subsequent releases.
In the end, velocity is sustainable only when speed does not create more recovery work.
Velocity becomes useful once it stops acting like a score and starts explaining how work actually moves. Throughout this article, the focus stayed on flow, delivery, and sustainability because those dimensions expose where time is spent, where work waits, and where recovery effort accumulates.
That framing helps shift conversations away from effort and toward observable system behavior that leaders can influence. As a result, velocity turns into a tool for decision-making instead of a source of tension.
If clarity matters in those discussions, contact Axify today to see how this framework maps onto your delivery system.
Developer velocity is measured by observing how long work waits, how often changes reach production, and how much rework or recovery they generate. This approach focuses on measurable system behavior rather than estimation, individual output, or sprint artifacts.
Metrics that reflect developer velocity measure how long work takes to move through the development process, how often it reaches production, and how much recovery it requires afterward. In this framework, that includes lead time for changes, cycle time, work in progress (WIP), deployment frequency, batch size trends, release regularity, rework rate, change failure rate, and review latency. Together, these metrics describe how the delivery system behaves end to end.
Deployment frequency is not a standalone velocity metric. It reflects how often code reaches production, which is only one part of delivery behavior. Without flow and stability context, frequency alone can hide queues, deferred work, and growing recovery effort.
Developer velocity can be measured outside of Agile, but it’s often harder to observe. Many non-Agile systems lack a consistent cadence, stable workflow stages, and comparable slices of work which are structures that make trends visible over time. Without them, velocity still exists, but it must be derived from explicit measurement of flow, release, and recovery behavior.