Performance de livraison
9 minutes de lecture

.webp?width=1200&name=Axify%20blogue%20header%20(8).webp)
Pourquoi certaines équipes d'ingénierie ont-elles du mal avec des déploiements lents, des versions imprévisibles et une gestion permanente des incidents, tandis que d'autres publient des logiciels de haute qualité de façon fluide et efficace ?
La différence ne réside pas seulement dans les compétences ; elle tient à la façon dont elles utilisent les données pour guider leurs décisions.
Une approche d’ingénierie pilotée par les données les aide à améliorer la qualité logicielle en suivant les indicateurs clés de performance, en analysant les tendances en temps réel et en exploitant des insights prédictifs.
Vous vous demandez comment les données peuvent optimiser vos processus d’ingénierie ? Ce guide explique les métriques utiles, les étapes concrètes à suivre et comment instaurer une culture pilotée par les données tout au long du SDLC.
Alors, commençons.
L’ingénierie pilotée par les données consiste à utiliser des métriques clés et des boucles de rétroaction continue pour obtenir des insights précieux. Cela vous aide à optimiser le développement logiciel même dans des systèmes complexes.
En pratique, les responsables techniques doivent prendre des décisions éclairées sur la base des données plutôt que de l’intuition, ce qui se traduit par :
Il existe des différences fondamentales entre les approches traditionnelles et pilotées par les données, que nous détaillons ci-dessous :
Les équipes traditionnelles mesurent l’efficacité de façon anecdotique, ce qui rend difficile l’identification de ce qui fonctionne réellement. Imaginez un manager déclarant « On a l’impression d’aller plus vite ». Mais à quelle vitesse ?
L’ingénierie pilotée par les données élimine ce flou en vous permettant de surveiller des métriques comme DORA, Flow et SPACE metrics (par exemple le temps de revue de PR, les handofffs ou le coding time). Elles fournissent des données objectives sur la performance du flux de travail.
Dans une configuration traditionnelle, les goulots d’étranglement n’apparaissent que lorsqu’ils deviennent critiques, comme un échec de déploiement de dernière minute ou une vague de rapports de bugs.
L’ingénierie pilotée par les données change la donne grâce aux analyses de décomposition du temps de cycle, au WIP, au throughput, aux analyses de PR, et plus encore, pour détecter les inefficacités avant qu’elles n’entravent la progression.
Nous vous recommandons la gestion de la chaîne de valeur pour éviter les goulots d’étranglement et fluidifier votre workflow.
Les dirigeants peinent à justifier leurs choix dans des cultures d’ingénierie traditionnelles mal comprises, car il n’existe souvent aucune preuve tangible pour étayer leur raisonnement.
En revanche, l’approche pilotée par les données s’appuie sur des chiffres clairs qui facilitent la communication de la génération de valeur auprès de la direction.
Dans les workflows classiques, la qualité du code n’est évaluée qu’après les échecs, généralement à la suite de plaintes clients ou de pannes. Cela freine l’innovation et augmente la dette technique.
Une démarche pilotée par les données permet de suivre en continu les métriques de qualité logicielle (taux d’échec des changements, fréquence des bugs, métriques de rework, etc.) pour repérer et corriger les défauts avant la mise en production.
Les indicateurs traditionnels mesurent souvent la productivité individuelle, comme le nombre de lignes de code écrites ou le nombre de tâches accomplies.
Avec l’ingénierie pilotée par les données, on met l’accent sur la productivité de l’équipe et son efficacité globale. Plutôt que de récompenser uniquement la quantité, il s’agit d’optimiser continuellement la performance des systèmes et la santé de l’équipe.
Mais il faut aussi aligner vos efforts de développement sur les résultats business. La recherche montre que les organisations qui privilégient l’impact utilisateur affichent 40 % de performance organisationnelle en plus que les autres.
Et soyez également judicieux quant à vos outils : par exemple, l’utilisation d’un cloud public accroît la flexibilité de l’infrastructure de 22 %, ce qui se traduit par une augmentation de 30 % de la performance globale.
Suivre les métriques clés d’ingénierie est le meilleur moyen de dépasser la simple production individuelle et de générer une productivité durable tout en améliorant l’impact business global. Passons maintenant à la suite.
Découvrons pourquoi cette approche n’est pas seulement utile ; elle change la donne :
Grâce aux KPI et aux modèles précis, vous gardez le cap sur les objectifs d'entreprise et les attentes des comités de direction. Au lieu de vous fier à l’intuition, vous pointez vers des données réelles.
Imaginez devoir moderniser votre infrastructure : plutôt que de la présenter comme une « amélioration nécessaire », vous utilisez un modèle prédictif pour démontrer son impact sur la performance et la fiabilité, et obtenir l’adhésion de la direction.
L’ingénierie pilotée par les données vous permet de passer de l’instinct aux décisions fondées sur :
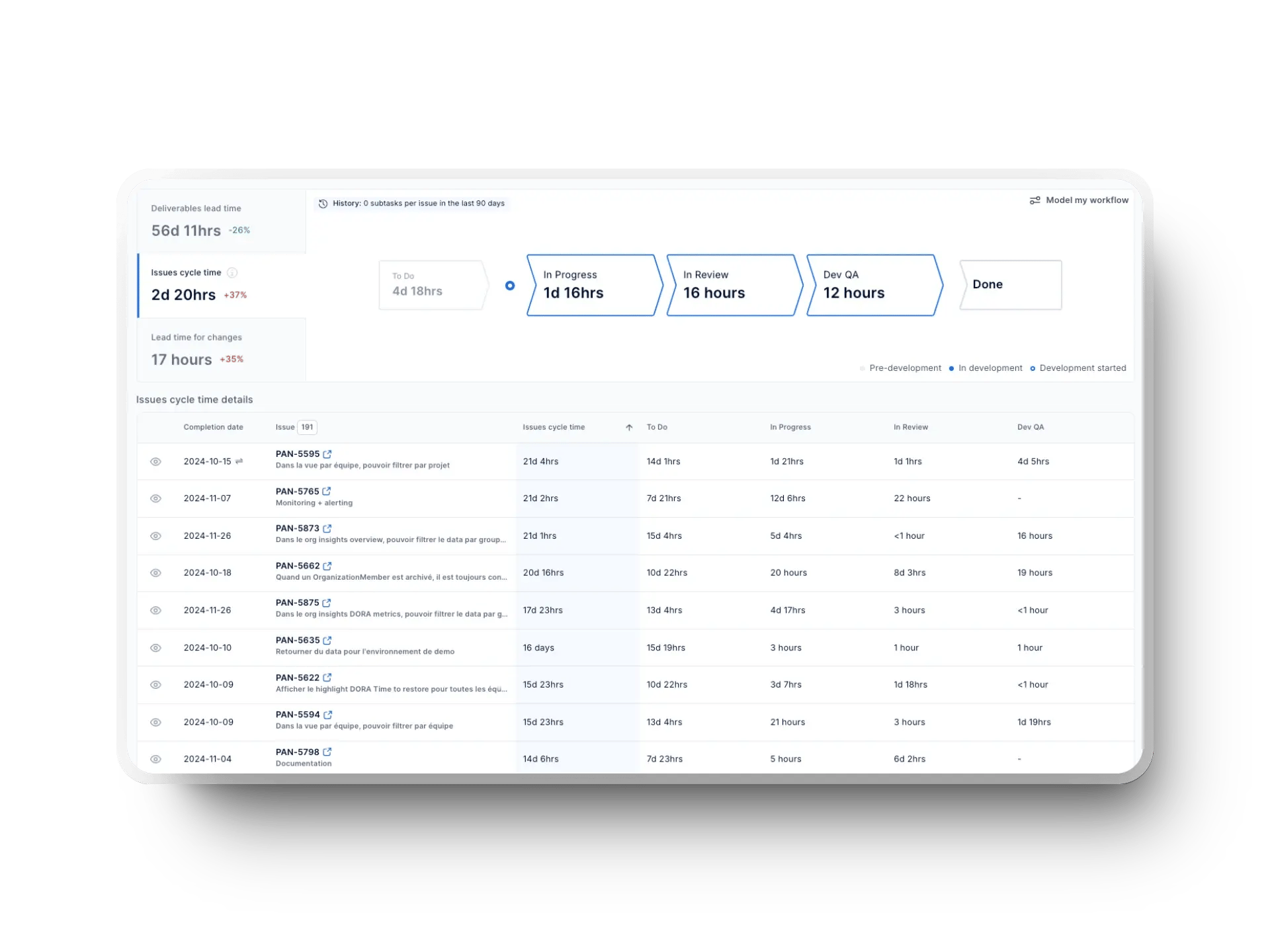
Exemple : les code repositories accumulent parfois des inefficacités invisibles. L’analyse du churn (taux de réécriture), du review time et du temps de cycle révèle les points de friction : un churn élevé signale des exigences floues, un long review time indique des réviseurs surchargés, etc.
Les goulots dans le processus de développement, la revue PR et les pipelines de déploiement ralentissent les projets. L’approche data-centric élimine ces blocages en mesurant des indicateurs d’efficacité opérationnelle tels que :
Ces insights vous permettent d’anticiper et de corriger les problèmes avant qu’ils n’impactent le taux d’échec.
Sans données, il est courant de mobiliser temps, budget ou effectifs sur des tâches à faible impact. L’approche pilotée par les données met en évidence où concentrer vos efforts pour maximiser la valeur grâce à la répartition des ressources.
Par exemple, si l’analyse montre que vos ingénieurs passent trop de temps aux tests manuels, vous pouvez réaffecter ces ressources à des frameworks de tests automatisés, libérant ainsi votre équipe pour résoudre des problèmes plus complexes.
Vous pouvez également utiliser l’outil de Value Stream Mapping pour repérer les goulots et déterminer où l’automatisation – ou d’autres solutions – aura le plus d’impact.
Les développeurs s’épanouissent lorsqu’ils codent, pas lorsqu’ils sont coincés en réunions ou occupés avec des tâches répétitives sans valeur ajoutée. L’ingénierie pilotée par les données permet de dégager ces distractions en automatisant les tâches à faible impact.
Grâce au cloud et à l’IA, vos équipes passent moins de temps sur des opérations manuelles (analyse de logs, etc.) et plus de temps sur de véritables problèmes d’ingénierie.
Selon McKinsey, le développement logiciel comporte deux boucles principales :
Maximiser le temps passé dans la boucle interne augmente la productivité et la satisfaction, tandis qu’investir dans l’outillage et l’automatisation de la boucle externe libère du temps pour l’innovation.
Dans l’ingénierie pilotée par les données, certaines métriques font véritablement la différence, notamment :
Attendre qu’un incident se produise n’est pas une stratégie. Les approches traditionnelles s’appuient sur des indicateurs retardataires (rapports post-mortem) qui ne révèlent les problèmes qu’après coup.
À l’inverse, l’approche data-driven privilégie les indicateurs avancés, fournissant un feedback en temps réel pour prévenir les incidents. Parmi eux : le temps de cycle, la fréquence de déploiement et l’efficacité du flux : ils anticipent les goulots et les risques plutôt que d’analyser les échecs passés.
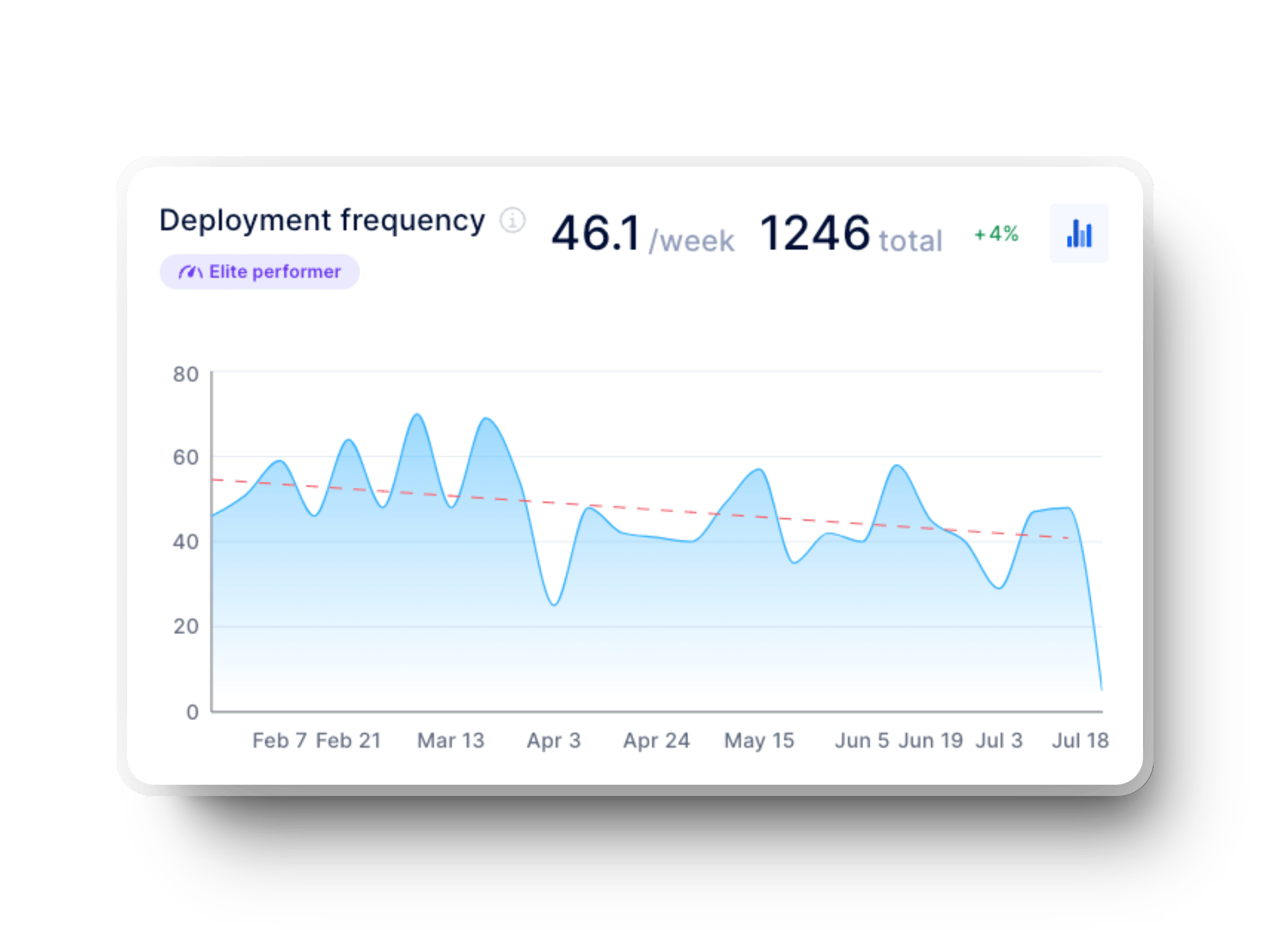
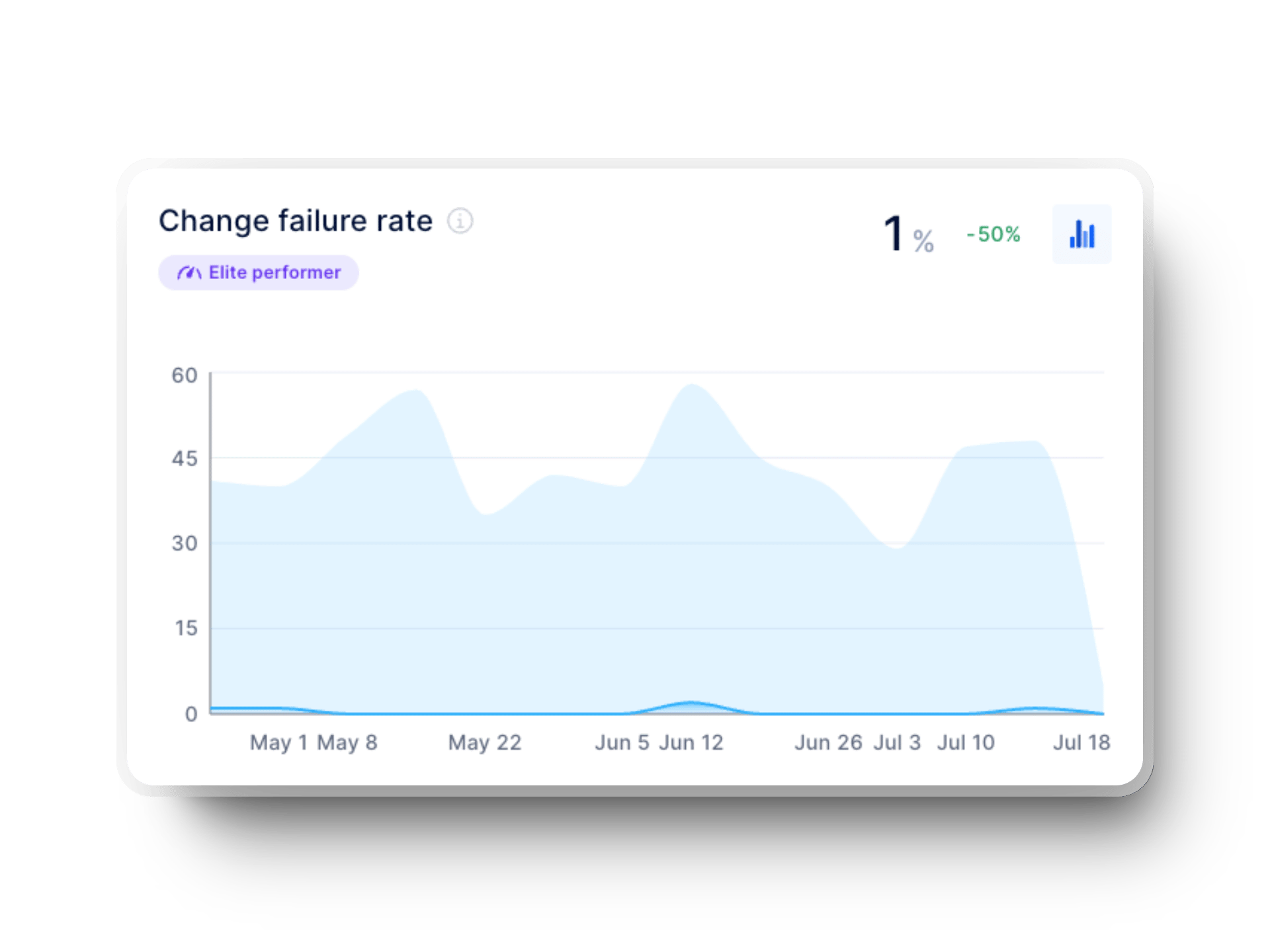
Des frameworks tels que DORA et Flow offrent de nombreuses métriques utiles pour l’ingénierie pilotée par les données, notamment :
Les métriques DORA (DevOps Research and Assessment) répondent à la question : « Notre processus de déploiement est-il efficace ou gérons-nous constamment des incidents ? » Elles comprennent :

%20in%20axify%20for%20software%20development%20teams.webp?width=1920&height=1440&name=time%20to%20restore%20service%20(dora%20metrics)%20in%20axify%20for%20software%20development%20teams.webp)
Les métriques Flow sont axées sur la valeur et indiquent la fluidité du travail dans le pipeline. En cas de lenteur de déploiement, elles aident à en déterminer la cause :

%20in%20Axify.webp?width=1920&height=1440&name=work%20in%20progress%20(WIP)%20in%20Axify.webp)
Tout en explorant les métriques clés à suivre pour l’ingénierie pilotée par les données, il est tout aussi important de connaître les pièges à éviter, tels que :
Un des plus gros pièges de l’ingénierie pilotée par les données est de travailler sur des changements sans impact réel. Supposons que vos tests automatisés s’exécutent en 20 heures et que vous les réduisiez à 18 heures. Si votre processus de publication reste ralenti par un goulot de 46 jours dans la revue de code ou la mise à disposition d’infrastructure, ce gain de deux heures ne fera rien avancer.
En résumé, concentrez-vous sur les améliorations qui apportent un retour clair et accélèrent réellement votre cycle de livraison.
Les métriques n’ont de valeur que lorsqu’elles sont reliées à vos objectifs. Sans cet alignement, vous risquez de poursuivre de mauvaises priorités. Par exemple, augmenter la fréquence de déploiement peut sembler un progrès, mais si ces versions ne sont pas stables ou n’améliorent pas la satisfaction client, elles n’ont pas de vraie valeur.
Cela signifie que chaque métrique suivie doit guider des actions directement alignées sur vos objectifs business, qu’il s’agisse d’améliorer la fiabilité ou l’expérience utilisateur.
Axify vous aide à suivre les objectifs pour mesurer les progrès de votre équipe par rapport aux objectifs d’entreprise.
![]()
Se focaliser sur une seule métrique conduit à de mauvaises décisions. Par exemple, si le temps de revue PR diminue, on se félicite d’un code plus rapide à déployer. Mais si la qualité en souffre, ces gains se paient par davantage de bugs et de régressions.
La solution ? Comme le recommande le framework SPACE, prenez du recul et combinez plusieurs métriques sur plusieurs dimensions. Ainsi, les progrès dans un domaine n’entraînent pas de régressions ailleurs. Dans cet exemple, vous pouvez également suivre le taux d’échec des changements et les incidents post-release.
Tout vouloir optimiser d’un coup ?
Suivre trop de KPI ralentit votre équipe. Vous passez votre temps à ajuster au lieu de livrer. Prenons l'exemple de la livraison de logiciels : la refonte du jour au lendemain peut sembler impressionnante, mais elle est virtuellement impossible. De petites améliorations constantes apportent plus de valeur qu’une refonte massive.
L’approche la plus intelligente consiste à se concentrer sur les métriques qui génèrent réellement de la valeur business et à laisser les autres de côté.
Lorsqu’on juge les individus à partir de métriques de productivité (par exemple, le nombre de PR fusionnées par semaine), on instaure un climat de peur plutôt qu’une culture de croissance. Si les développeurs savent qu’on compte leurs lignes de code, ils risquent de produire un code gonflé pour atteindre l’objectif.
Il vaut mieux privilégier les tendances d’équipe et les métriques collaboratives, comme les métriques DORA, pour obtenir une vue d’ensemble de l’efficacité.
Se fier uniquement aux données peut conduire à de mauvaises hypothèses. Un temps de cycle élevé peut sembler un signe de lenteur, alors que la cause réelle peut être des exigences floues ou des outils obsolètes.
La bonne méthode consiste à combiner le feedback qualitatif des ingénieurs avec des insights quantitatifs pour identifier les véritables goulots.
L’usage optimal des métriques d’ingénierie repose sur ces principes :
Cette approche alimente chaque étape du cycle de vie logiciel (SDLC) avec des données et transforme les insights en actions :
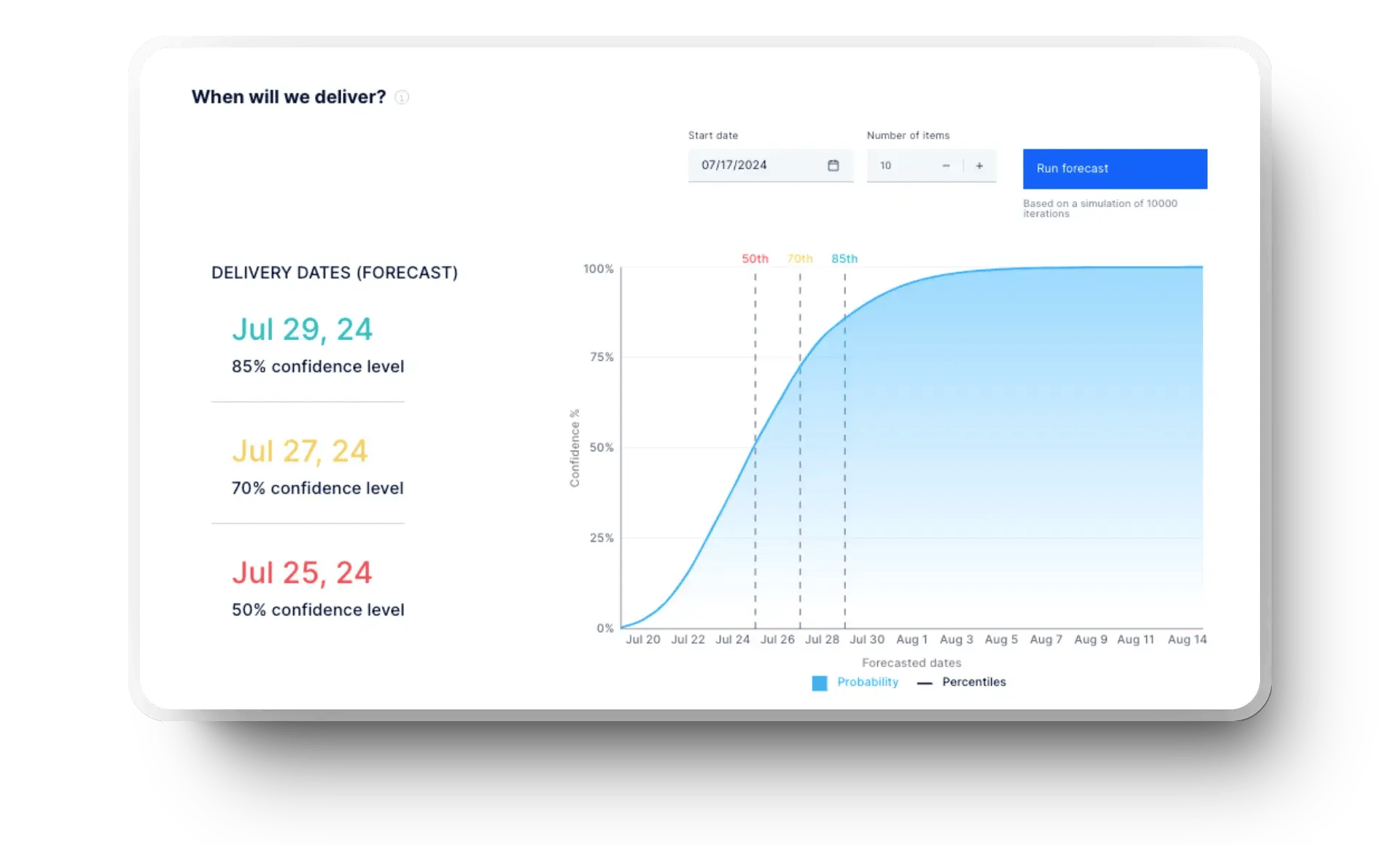
Les équipes qui se fient à l’intuition pour planifier les sprints ratent souvent les échéances et surchargent leurs ingénieurs. Servez-vous plutôt des données historiques de débit et des tendances du temps de cycle pour estimer la capacité de sprint sur la base de la performance réelle, non de cibles arbitraires.
Suivez également les tendances d’achèvement des tâches pour éviter les déséquilibres de charge. Lors de la planification, priorisez les retours clients et les données de défauts récurrents afin de livrer à temps, avec un impact maximal et en préservant le bien-être de l’équipe.
En phase de développement, réduisez les reworks en surveillant le taux d’échec des changements et les tendances de rework, ce qui aide à repérer tôt les fonctionnalités et stories à haut risque. Par exemple, si une fonctionnalité est sans cesse annulée, c’est le signe de tests manquants ou de dépendances instables – détectez-le tôt pour éviter les corrections de dernière minute.
L’ingénierie pilotée par les données permet aussi d’identifier les goulots d'étranglement dans le temps de cycle de revue des PR, améliorant ainsi la collaboration. En cas de blocages répétés, c’est souvent dû à des réviseurs surchargés, des retours peu clairs ou un processus trop lent. Corrigez ces failles pour obtenir des fusions plus rapides et moins de frustration pour tous.
Rien ne freine plus qu’un processus de revue de PR interminable. Lorsque les validations traînent, ce n’est pas seulement le code qui est en cause, mais aussi des retours flous ou des workflows inefficaces. Suivez les tendances de temps de revue pour identifier l’origine des retards et corrigez-les avant qu’ils n’impactent la productivité.
Concernant la fusion, si les PR stagnent, quelque chose cloche : stratégies de brancing complexes, validations manuelles ou manque d’automatisation. Mesurer les temps de fusion est un véritable atout pour fluidifier le processus et maintenir un flux de mises à jour constant sans sacrifier la qualité du code.
Déployer du code ne signifie pas simplement le publier ; il faut fournir des mises à jour stables et de haute qualité sans interruptions. La fréquence de déploiement est une métrique clé pour cela : elle permet de repérer les tendances dans le release cycle pour que les releases soient réguliers plutôt qu’imprévisibiles.
L’évaluation du lead time for changes est tout aussi essentielle. Cette métrique data-driven permet d’identifier rapidement les lenteurs dans les tests et les validations pour optimiser vos pipelines CI/CD. L’analyse du taux d’échec des changements révèle les points faibles dans les étapes de validation afin d’empêcher le code instable d’atteindre la production.
La collecte de données d’incidents en temps réel permet à vos équipes de détecter rapidement les problèmes et de réduire les temps de récupération après un déploiement raté. De plus, le suivi des bugs remontés par les clients et des régressions de performance post-release offre un aperçu précieux de l’expérience utilisateur, pour prioriser les corrections à fort impact.
Enfin, analyser les tendances des déploiements échoués dans le temps révèle des tendances. Avec ces informations, vous pouvez ajuster vos stratégies de release, renforcer les processus de validation et livrer des mises à jour toujours plus stables et qualitatives.
Envie de mettre en place une culture data-driven ? Suivez ces étapes claires :
Adopter une approche pilotée par les données comporte des défis, mais voici des solutions pratiques pour les surmonter :
Prêt à adopter une culture pilotée par les données dans votre workflow logiciel ? Axify propose plusieurs fonctionnalités clés :
Faites des données votre allié. Commencez votre parcours avec Axify dès aujourd’hui en réservant une démo !
